Over the course of working on PSRayTracing (PSRT), I've been trying to find all sorts of tricks and techniques to squeeze out more performance from this C++ project. Most of it tends to be alternative algorithms, code rewriting, and adjusting data structures. I thought sprinkling the final keyword like an all purpose seasoning around every class was "free performance gain". But... that didn't really turn out to be the case.
Back in the early days of this project (2020-2021), I recall hearing about the noexcept keyword for the first time. I was reading through Scott Meyer's works and picked up a copy of "Effective Modern C++" and watched a few CppCon talks about exceptions. I don't remember too much, but what I clearly recall:
- Exceptions are slow, don't use them
noexceptwill make your code faster
I re-picked up a copy of the aforementioned book whilst writing this. "Item 14: Declare functions noexcept if they won't emit exceptions" is the section that advocates for this keyword. Due to copyright, I cannot post any of the text here. Throughout the section the word "optimization" is used. But, it neglects any benchmark.
For those of you unfamiliar with noexcept, here is the nutshell explanation: you can use it to mark if a function will not throw an exception. This is useful for documentation and defining APIs. Personally, I really like that the keyword exists.
Similar to what I did for the final keyword, I created a NOEXCEPT macro that could be used to toggle on/off the use of noexcept at CMake configuration time. This way I could see by how much the keyword could improve throughput by.
When I did the initial A/B testing, I don't recall seeing that much of a speedup. The rendering code (which is what is measured) had zero exceptions from the start. PSRT does have a few, but they are all exclusively used in setup; not during any performance critical sections. I still left it in (and turned on) because it didn't seem to hurt anything and potentially help.
Back in April 2024 when I published that one article about my findings of final's performance impact, I submitted it to CppCast via email. Timur Doumler (one of the co-hosts) asked me if I had any performance benchmarks about the use of noexcept. I did not.
But since the time I first added in NOEXCEPT, I had created automated testing tools (which also tracks the performance) and an analysis suite to view the data. I decided to re-run all of the same tests (including more), but this time to truly see if noexcept actually does have some impact on performance.
The short answer is: yes, but also no; it's complicated and silly.

Prior Art
In his email, Mr. Doumler told me that no one else in the C++ community had yet to publish any benchmarks about the keyword; to see if it actually did help performance.
At first, I wasn't able to find any. But eventually I did stumble across a 2021 answer to a 2013 stack overflow question. vector::emplace_back() was found to be about 25-30% faster if noexcept was being used. Fairly significant! But this lacks telling us what CPU, OS, and Compiler were used.
In the 11th hour of writing this, I found a lighting talk from C++ on Sea 2019. Niels Dekker (while working on ITK) did his own version of the NOEXCEPT macro along with benchmarks. He is reporting some performance improvements, but his talk also said there are places where noexcept was negative. One other finding is that it was compiler dependent.
And, that's about it. From cursory Googling there is a lot of discussion but not many numbers from an actual benchmark. If any readers happen to have one on hand, please message me so I can update this section.
How Does noexcept Make Programs Faster?
This is something I had some trouble trying to figure out (and I don't seem to be the only one). An obvious answer could be "because it prevents you from using exceptions that slow down your code." But this isn't satisfactory.
Among performance minded folks, there is a lot of hate for exceptions. GCC has a compiler flag -fno-exceptions to forcibly turn off the feature. Some folks are trying to remedy the situation by providing alternatives. Boost itself has two: Outcome and LEAF. Right now LEAF seems to be winning in terms of speed.
Kate Gregory wrote an article entitled "Make Your Code Faster with noexcept" (2016) that provides more insight. Quote:
First, the compiler doesn't have to do a certain amount of setup -- essentially the infrastructure that enables stack unwinding, and teardown on the way into and out of your function -- if no exceptions will be propagating up from it. ...
Second, the Standard Library is noexcept-aware and uses it to decide between copies, which are generally slow, and moves, which can be orders of magnitude faster, when doing common operations like making a vector bigger.
While this provides how noexcept can help performance, it neglects to provide something important: a benchmark.
Why "Don't Use noexcept"?
I didn't understand this either. I couldn't find many (simple) resources advocating for this camp. I found a paper (from 2011) entitled "noexcept Prevents Library Validation". I'm not sure how relevant it is 13+ years later. Else, Mr. Doumler sent me a good case via email:
Meanwhile, sprinkling
noexcepteverywhere causes lots of other problems, for example if you want to use things like a throwing assert for testing your code that just doesn't work.
Assertions are great for development and debugging; everyone loves them. They are absolutely vital to building any major C/C++ project. This is something I do not want taken away.
Personally, I like the noexcept keyword. It's very useful for documentation and telling others how to use code. We've all been burned by an unexpected exception at some point. It's nice to have in the language in my opinion for this reason.
How This Test Works
It's the exact same as the last time for what I did with final. But for those of you who aren't familiar, let me explain:
- It's a simple A/B test of the
noexceptkeyword being turned on and off with the same codebase - The test is an implementation of Peter Shirley's Ray Tracing in One Weekend book series
- It's fully CPU bound and vanilla-as-possible-modern-standard-C++
- All scenes from the book are rendered 50 times without
noexceptturned on- Each test case has slightly different parameters (e.g. image size, number of cores, random seed, etc.)
- One pass can take about 10-20 hours.
- Only the time spent rendering is measured (using nanoseconds)
- Once again, we repeat the above, but with
noexceptturned on - The off vs. on time difference is calculated as a percentage
- E.g.
off=100 msandon=90 ms. Speedup is 10 ms, so we say that's an +11% performance boost
- E.g.
- All of the above is repeated for a matrix of different chips (AMD, Intel, Apple), different operating systems (Linux, Mac, Windows) and different compilers (GCC, clang, MSVC). This time I tested 10 different configurations
All of the code was built using CMake and compiled with Release mode on, which should give the most performant runtimes (.e.g GCC/clang use -O3 and MSVC has its equivalent).
One important thing I do need to state about this test:
Unfortunately, 100% of all images rendered did not come out the same. The overwhelming super majority did; and when they were different it's negligible. When I first worked on this project I didn't know std::uniform_int_distribution doesn't actually produce the same results on different compilers. (A major issue IMO because that means the standard isn't really portable). A few scenes (such as Book 2's final scene) use an RNG to place objects and generate some noise textures. For example, GCC & MSVC (regardless of CPU/OS) seem to produce the exact same scene and same pixels. But clang has a few objects in different positions and some noise is different. Surprisingly, it is mostly intact compared to the other two. I find this astonishing. But I don't think the difference is that much to require a redo of the experiment. You can see the comparisons in this hefty .zip file.
This discrepancy shouldn't matter that much for two reasons:
- The differences are not too significant (see the .zip linked above if you're skeptical)
- The comparison is
<CHIP> + <OS> + <COMPILER> with <FEATURE> offvs.<CHIP> + <OS> + <COMPILER> with <FEATURE> on
With this said, at the end I do some fun number crunching in a Jupyter notebook and show you some colourful tables & charts alongside analysis.
Please keep in mind that this is a fairly specific benchmark. The (initial) goal of PSRT was to render pretty CGI pictures really fast (without breaking the original books' architecture). It works in a mostly recursive manner. Different applications such as financial analysis, protein folding simulations, or training AIs could have different results.
If you're wondering how I can turn off and on the use of noexcept, it works by (ab)using preprocessor macros:
And thus we powder it all around the code like so:
Once again, this is something I would never EVER do in production code; and you shouldn't either.
Also, I am (now) aware there is noexcept(true) and noexcept(false) that I could have done instead. I didn't know about it at the time and did this ugly C macro. Please forgive me merciless internet commentators.
Almost every function in this project has been marked with this macro. There are a few... exceptions... but these are in the setup or teardown sections of the program. None are in any of the rendering code (which is what is measured). This should allow us to see if marking functions as noexcept help performance or not.
PSRayTracing is not a "real world" application. Primarily serving as an amateur academic project, it does try to be modeled based on real world experiences. Personally, I do believe that commercial products like Unreal Engine or Pixar's RenderMan can serve as better benchmarking tools in general. But I have no idea about their ability to A/B test the C++ language, algorithms, data structures, etc. This is something PSRT has been set up to do.
Results From The Suite
Running the entire test suite an exhausting 22 times, it took cumulatively an absolutely melting 370 hours 🫠🫠
One thing I need to note is the AMD+Windows runs are "artificial" in a sense. When I did the initial analysis I noticed some of the variance in the data was higher than desired. So I ran the suite a second time (once for GCC and MSVC), but for each test case I took the fastest runtime between both attempts. This way AMD+Windows could be given the best chance possible.
So, does noexcept help performance? Here's the grand summary:

We can see here that in some configurations, noexcept gave a half to full percent performance increase; which I think unfortunately could be declared fuzz. In the situations where there was a drop, it's around -2% on average. noexcept isn't really doing that much; it's even acutely harmful for performance. Bar charting that data:
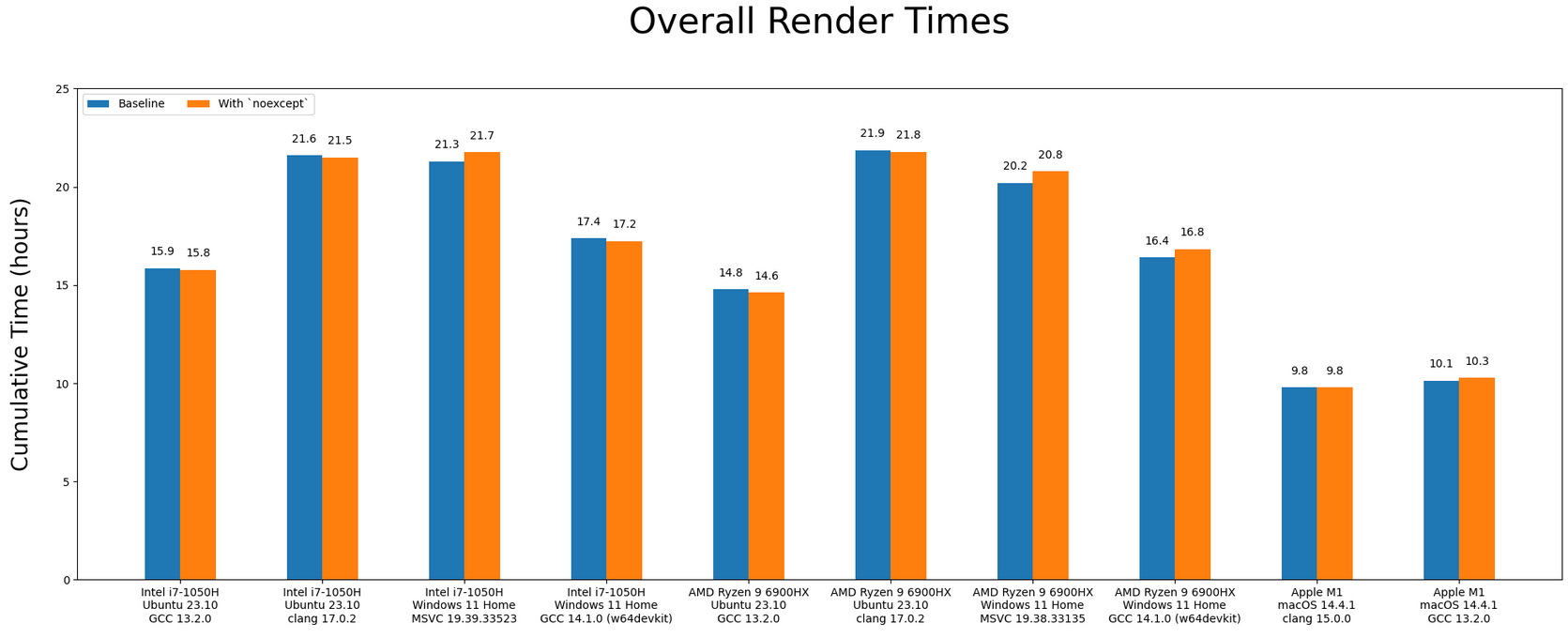
I do need to remind: this is not supposed to be a Monday Night Compiler Smackdown cage match, but once again there are interesting things to observe:
- Like last time, the Apple Silicon trounces everything else, and by a significant amount
- clang (on Linux) is considerably slower than GCC
- If you were to overlay the AMD bars on top of the Intel ones, it almost looks the same
- Your OS (the runtime environment) can have a significant impact on throughput. GCC is doing way better on Linux than Windows.
Summaries are okay, but they don't tell the whole picture. Next, let's see how many of the test cases had a performance increase. While a 1% speedup could not seem like much, for some applications that does equal a lot in cost savings.
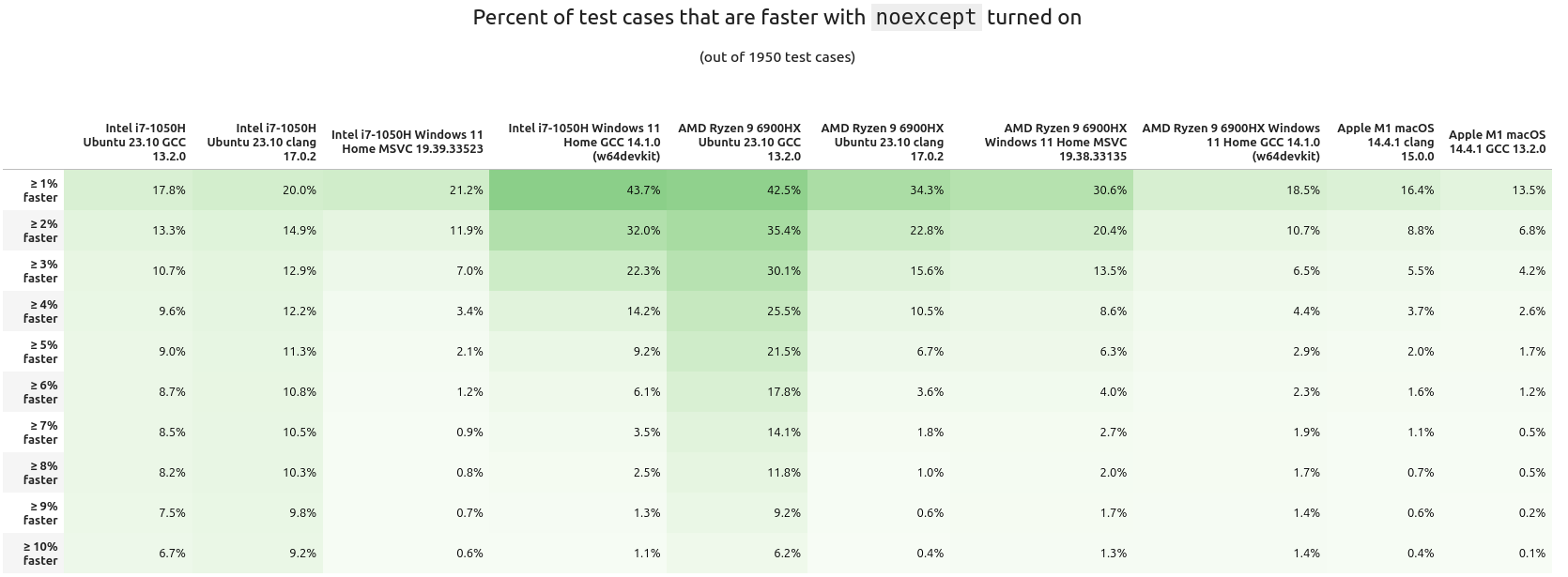
What about the inverse? Here are the percentages of tests having a slowdown with noexcept:
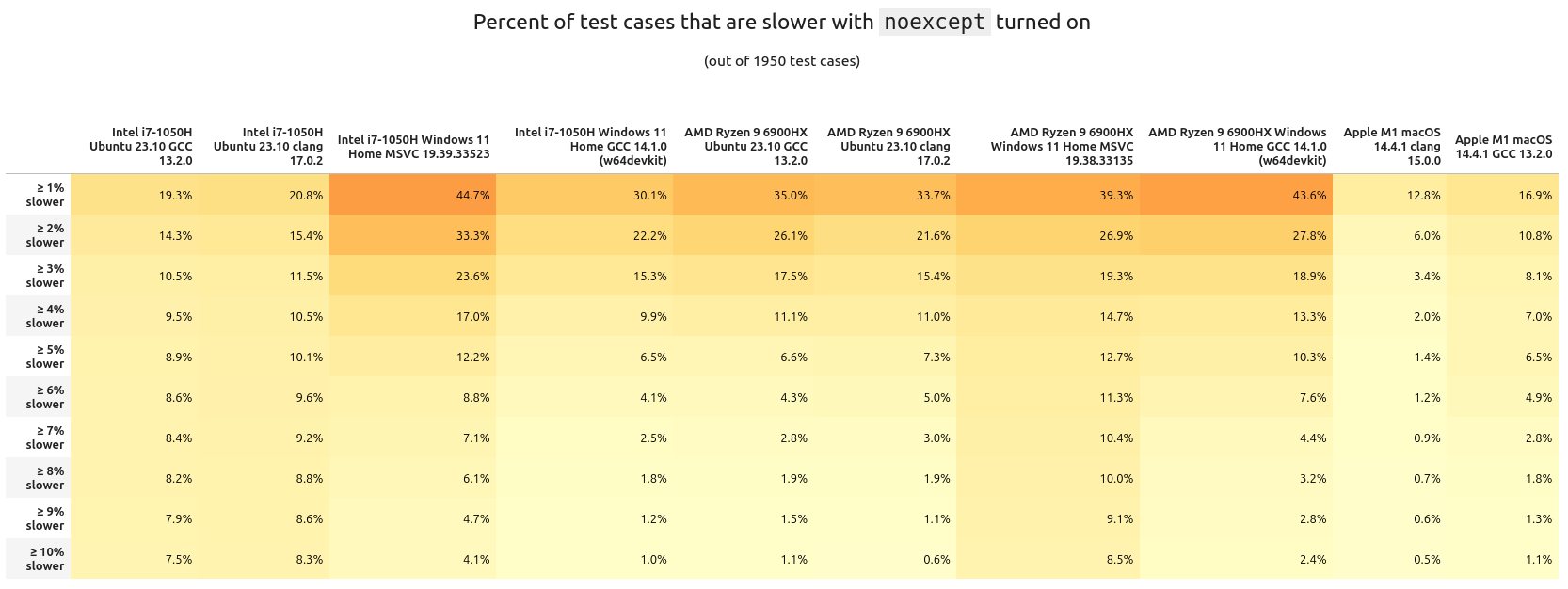
I don't think there's too much we can glean from these tables other than the runtime delta typically stays within the (very) low single percents. Looking at it per scene tells a different story:
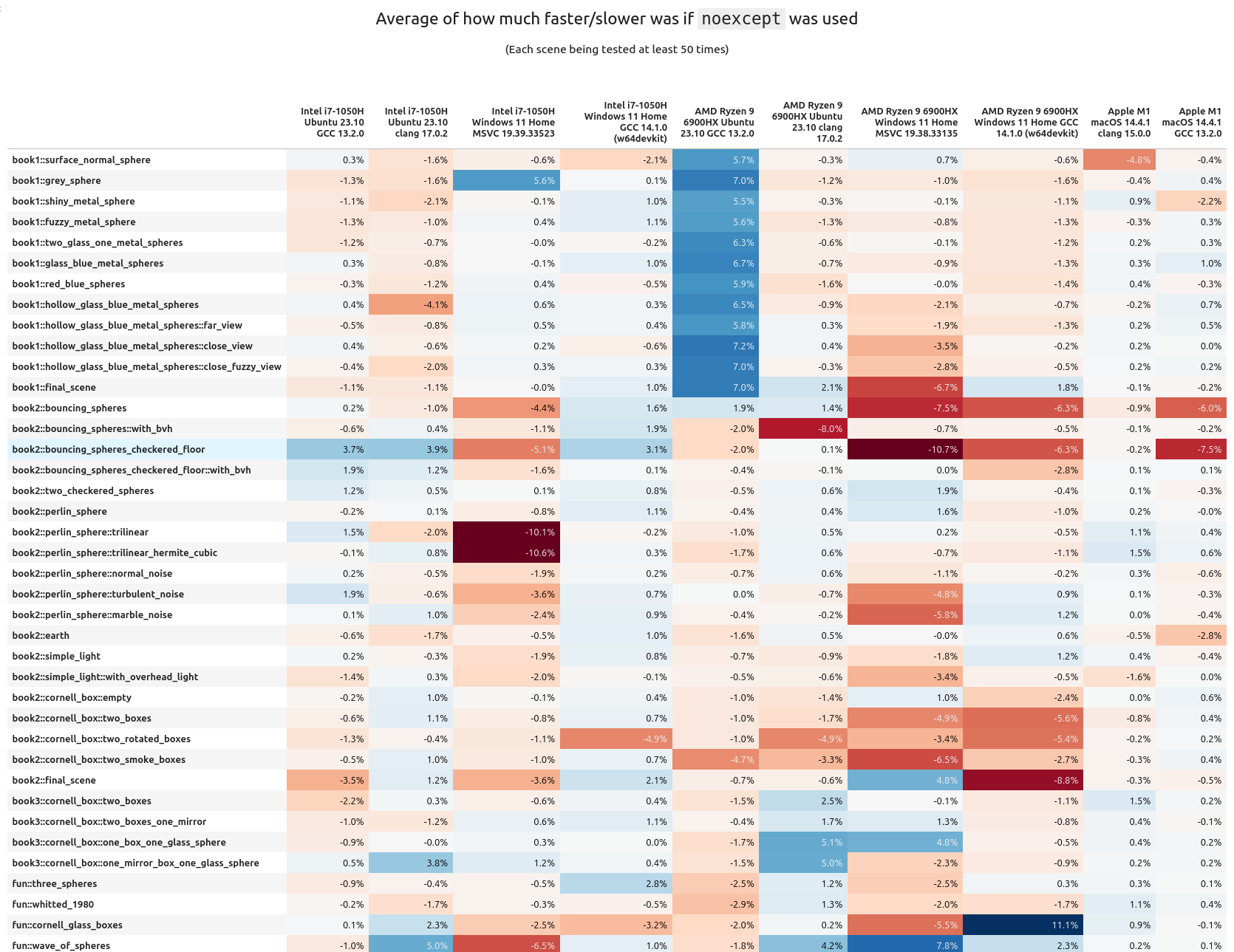
When we look at the average "percentage performance delta per scene", we can clearly see there are some scenes that benefit quite well from noexcept, others are getting hit quite hard. It's also interesting to note how many scenes are barely helped or hurt. Means are good, but seeing the median gives a more fair look at the results. When that is done with the above data, noexcept looks to be less impactful:
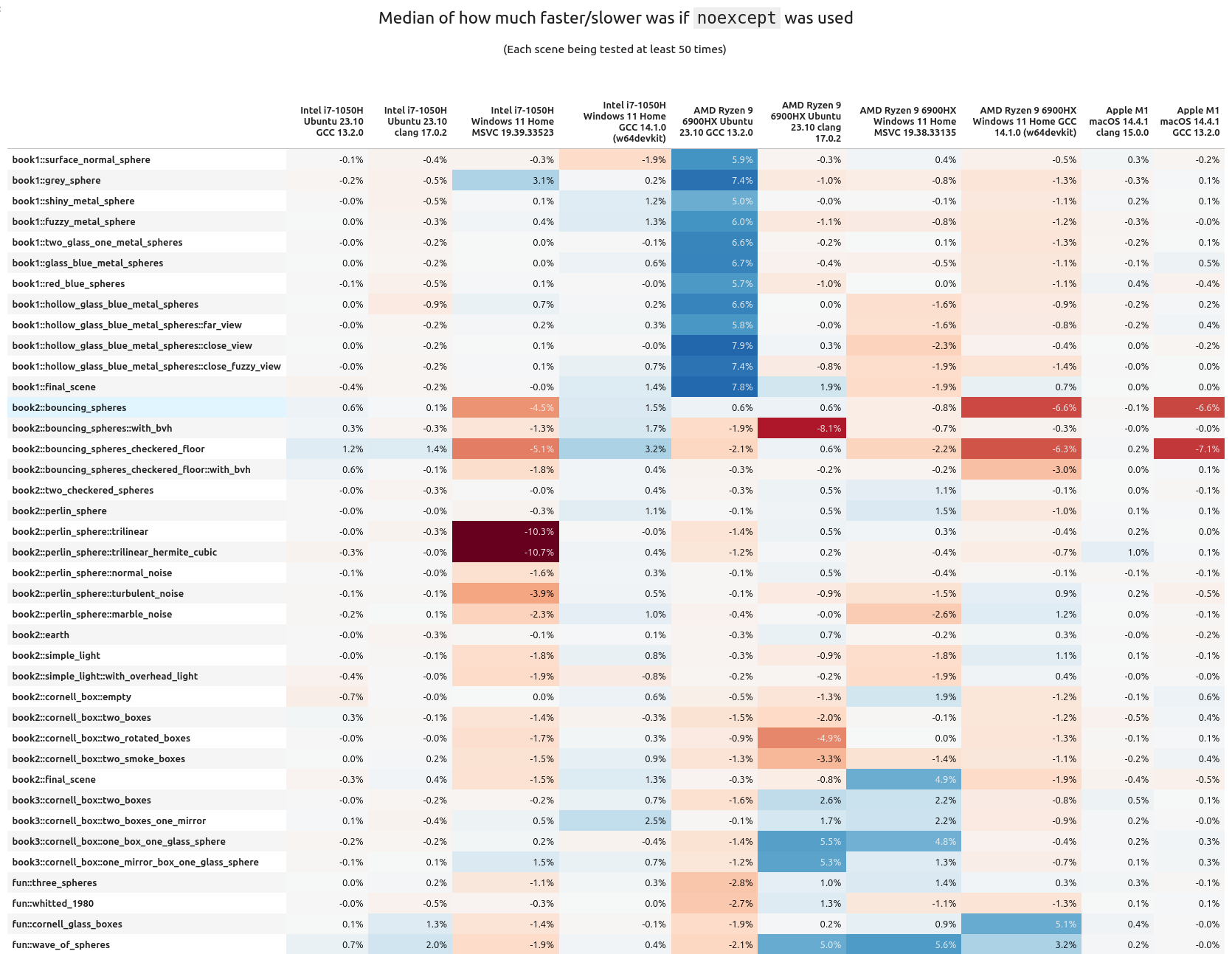
If you want to look at the variance, I have the table right here. I don't think it's as interesting as the above two (though you can have it anyways).
{kind=link}
So overall, it mostly looks like noexcept is either providing a very marginal performance increase or decrease. Personally, I think it is fair to consider the measured performance increase/hit from noexcept to be fuzz; that means it kind of does nothing at all to help runtime speed.
There are some interesting "islands" to take a look at from the above chart.
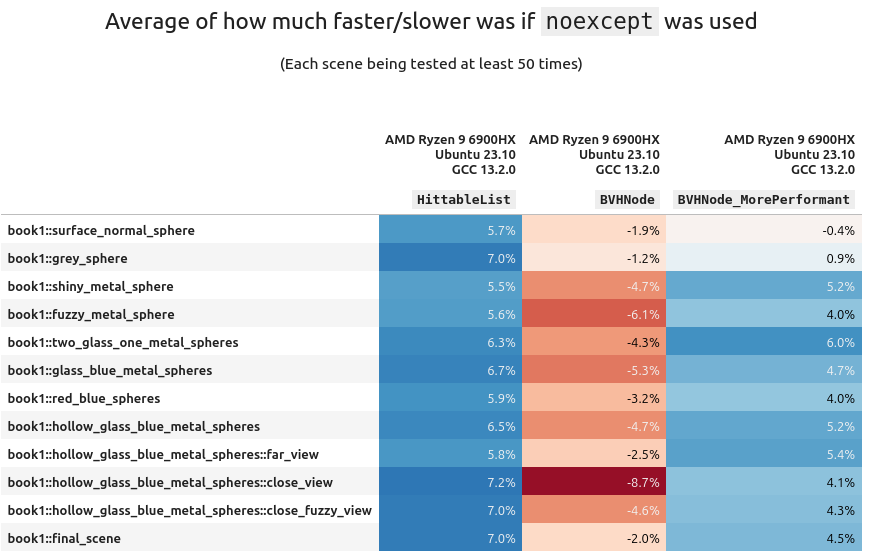
The AMD+Ubuntu+GCC configuration
We actually see a very significant and consistent performance boost of 6-8% with noexcept turned on! But this is only for the scenes from book 1. When I first saw this I was wondering what could have caused it, and eventually I realized it was related to the architecture of the scene geometry from the first book.
All scene data is stored inside of a std::vector called HittableList. For these scenes, when the ray tracer is traversing through the scene geometry it's doing a sequential search; this was done for simplicity. Any practical graphics engine (realtime or not) will use a tree like structure instead for the scene information.
Starting in book 2 the second task is to use a BVH to store the scene. This provides a massive algorithmic boost to the performance. All subsequent scenes in this book use a BVH instead of a list of objects. This is why we don't see that same speedup in Book 2 (and in fact, a minor performance hit).
From up above, if you remember one of the arguments for "noexcept is faster" is the standard library is aware and can use (faster) memory move operations instead of (slower) copy operations. This is most likely the cause of the performance increase. But the BVH node is not part of std::, and doesn't have move constructors implemented. Therefore when using it noexcept does nearly nothing.
What is more fascinating is that the boost was only seen on AMD+Ubuntu+GCC configuration. Swap out any one of those variables (CPU, OS, or compiler) and no significant gain (in fact a tiny loss) was observed.
Digging A Little Bit Deeper
So... There's actually two BVH tree implementations in PSRT. One of them is the original from book 2. The other one is something I cooked up called BVHNode_MorePerformant. It's 100% API compatible with the standard BVHNode. But under the hood it works a little differently. The quick gist of it: instead of using a tree of pointers to store and traverse, the data is stored in a std::vector in a particular order. The traversal is still done in a tree-like manner, but because of the memory layout of what needs to be checked it can be more efficient. Years ago when I first wrote and tested this class I did see a small speedup in lookups.
It might be good to measure replacing HittableList in book 1 (on AMD+Ubuntu+GCC) with both BVH implementations and see the results:

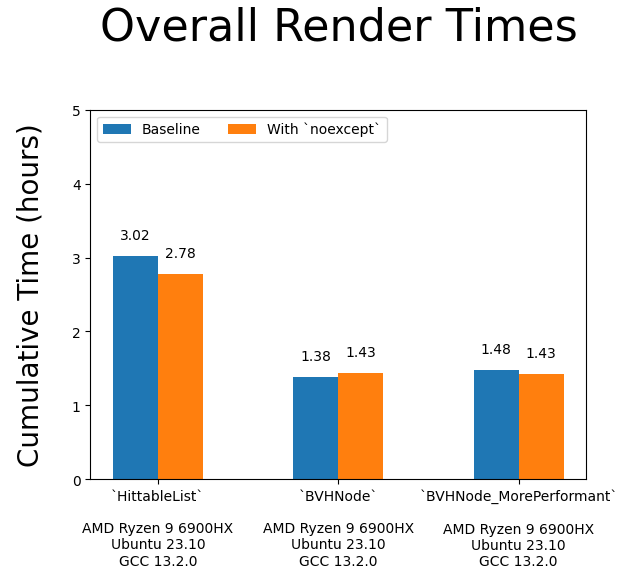
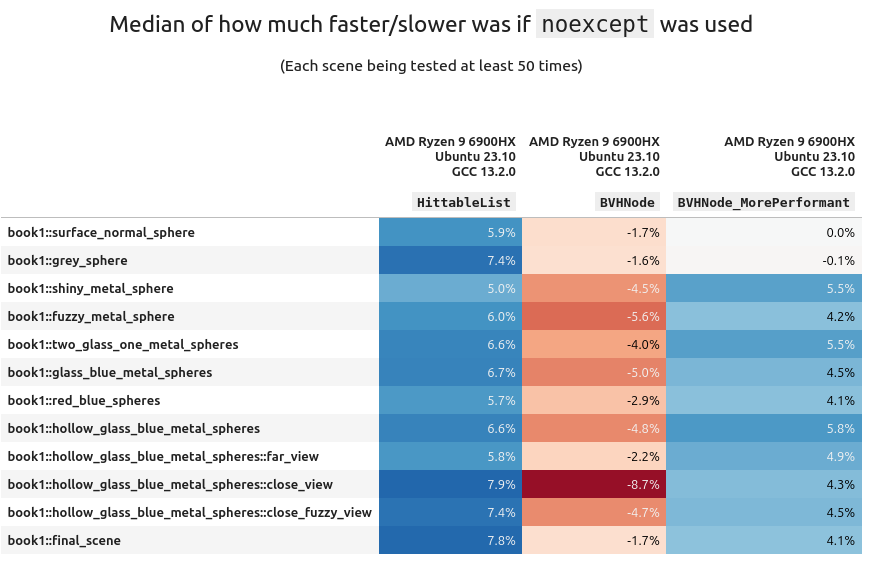
(Variance table available here if you're interested (it's boring)).
{kind=link}
Using std::vector with a dash of noexcept in your code will make that container faster. But we have to remember it's algorithmically inefficient compared to a BVH. And slapping noexcept on top of that (the BVH) can actually be harmful!!. And much to my dismay, my BVHNode_MorePerformant was beaten by the book's default implementation 😭
Shortly below there is a secondary benchmark that has a "reduced" version of HittableList across the configurations. But I would like to address a few other points of interest.
Intel+Windows+MSVC
Looking at the mean/median tables from further above, the Intel+Windows+MSVC run seems to get a little bit of a hit overall when using noexcept. The book2::perlin_sphere:: series of tests steer towards a negative impact. And there are two scenes that have a whopping -10% performance hit with the keyword enabled!!

I am wholly confused as to why this is happening. As you can see, they are pretty simple scenes. Looking at the two cases with the larger performance hit, they are using trilinear interpolation (hermetic and non-hermetic). The code is right here. There are some 3-dimensional loops inside of the interpolation over some std::array objects. This is maybe the source of the slowdown (with noexcept on) but I do not want to speculate too much. It's a very minor subset of the test suite..
If you look at the source code, those three dimensional loops can be manually unrolled, which could (and I stress "could") lead to a performance boost. Sometimes the compiler is smart enough to unroll loops for us in the generated assembly. I didn't want to do it at the time since I thought it was going to make the code overly complex and a maintenance nightmare. This is something to take a look at later.
Looking (a little) More At std::vector
I think it is fair to conclude using std::vector, with noexcept does lead to a performance increase (compared to without the keyword). But this is only happening on one configuration.
I thought it would be best to write up a small testing program (that operates just like HittableList). It does the following:
- Generate a list of random numbers
- Generate a number to search for (could be out of range)
- Try to find that number in the list
- With this part we turn on/off
noexcept
- With this part we turn on/off
The program (of course) was compiled with -O3 and was supplied the same arguments across each configuration. It's run like this and here is the output:
ben@computer:folder$ ./list_test_clang_17 1337 9999999 10000 Checking 9999999 elements, 10000 times... plain average time: 2976 us `noexcept` average time: 2806 us plain median time: 2982 us `noexcept` median time: 2837 us
After testing on each configuration these were the grand results:
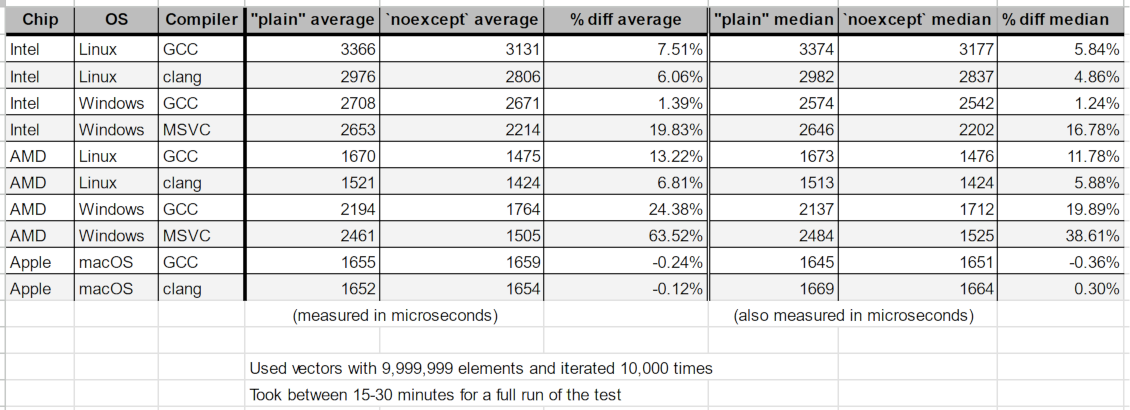
This is a very limited test. We can see there is a fairly consistent speedup for all x86 cases (and a very nice one for AMD+Windows). Apple Silicon has nothing and is likely fuzz.
The people who like noexcept might find this validating, but it's at odds with the tables from measuring PSRT: The speedups here aren't being matched with all the results from book 1, which uses the same "sequential search in std::vector" technique.
Look at the median chart from above. The only reliable speedup came from AMD+Linux+GCC, of around +7%. All other configurations were flat or possibly fuzz. In this mini test AMD+Linux+GCC meters 12% and many other configurations have a significant positive impact from noexcept.
In a more complex program the speedup wasn't reproducible.
From the last article, a commenter on HackerNews mentioned how they didn't like PSRT as a benchmark because it was too large. They preferred tests of small components. This is absolutely ludicrous since as software developers we're not writing small programs. We are building complex systems that interact, move memory around, switch contexts, invalidate cache, wait on resources, etc.
Just because a speedup is seen for a single component doesn't mean it will show up later when programs become large and have a lot of moving parts.
Hopefully I've illustrated this point.
Looking At The Assembly
C++ isn't what's running on the CPU, it's the generated assembly code. Usually to prove that something is faster, I've seen other articles post the generated assembly code, saying "It's optimized!!" I saw this for final, but what is noexcept doing?
Using the above testing program, let's see what the difference is in the generated x86 assembly (from GCC 13 with -O3):
These two look... oddly the same. I'm only spotting one difference, this line where the arguments are swapped in order:
{kind=link}
< cmp DWORD PTR [rdx+rax*4], esi --- > cmp esi, DWORD PTR [rdx+rax*4]
I'm not well versed in assembly, but what I can tell from documentation, it doesn't seem like the order of arguments from the cmp instruction instruction matter. If they do, someone please tell me so I can correct this information. I'd be VERY surprised if this swapped order is what caused the speedup in the limited benchmark above. Anyone who understands assembly much better than I, please provide insight. I would be grateful.
Assembly inspection usually can give insights, but it's no excuse for not measuring your code.
Wrapping up this detour into std::vector, other STL containers might have a performance increase, but we do not know for certain. Thus far only measurements from std::vector have been taken. I have no idea if something like std::unordered_map is impacted by noexcept. There are many other popular alternative container implementations (e.g. Boost, Abseil, Folly, Qt's). Do these get helped, hurt, or placebo'd by noexcept? We don't know.
And keep in mind, in the context of PSRT, we only saw a consistent speedup on one specific configuration (out of ten); some even saw a minute drop. The CPU, OS, and compiler play a role.
I really question whether noexcept helps performance. Just like with final, it doesn't seem to be doing much. Some cases it helps, other cases it hurts. We did find one solid case for Book 1 with AMD+Linux+GCC; but that's it.
And after seeing that overall hit/gain can be from -3% to +1%, I've actually become skeptical and decided to turn it off. I still like the keyword as a documentation tool and hint to other programmers. But for performance, it mostly looks to be a sugar pill.
My most important advice is the same as last time: don't trust anything until you've measured it.
Last Notes
I really didn't think I was going to be running such a similar test again and so quickly. This has inspired me to take a look at a few other performance claims I've heard but yet to have seen numbers posted for.
As for the benchmark itself, I would have loved to throw in some Android and iOS runs as well, but I do not have the bandwidth for that, or infrastructure to make it possible unless I were to quit my day job. We don't have too much high performance computing on mobile and ARM chips yet, but I can see it being something in the future. This is one of the deficiencies of this test. I'd really like to throw Windows+clang into the mix too, but right now there isn't a turnkey solution like how w64devkit provides GCC for Windows. Embedded and other "exotic" chips/runtimes have been given any love either. Maybe even playing with an IBM z16 might be fun 😃
PSRT doesn't also have a good way to "score" how intense a scene is. E.g. number of objects, what kinds, how complex, what materials, textures, lighting, etc. All that can be done right now is "feature on vs. feature off". I'd also want to expand this to other applications out side of computer graphics too.
If you want to follow what goes on with PSRayTracing, check out the GitHub page and subscribe to the releases. But do note the active development is done over on GitLab. You can find all of my measurements and analysis tools in this section of the repo.
EDIT Aug. 10th 2024: There has been discussion about this article on /r/cpp and Hacker News. Read at your leisure.
Till next time~
Vector Pessimization
(This section was added on Aug. 24th, 2024)
I wanted to give it about two weeks before reading the comments in the discussion threads (see above). On Hacker News there was an insightful comment:
... The OP is basically testing the hypothesis "Wrapping a function in `noexcept` will magically make it faster," which is (1) nonsense to anyone who knows how C++ works, and also (2) trivially easy to falsify, because all you have to do is look at the compiled code. Same codegen? Then it's not going to be faster (or slower). You needn't spend all those CPU cycles to find out what you already know by looking.
There has been a fair bit of literature written on the performance of exceptions and noexcept, but OP isn't contributing anything with this particular post.
Here are two of my own blog posts on the subject. The first one is just an explanation of the "vector pessimization" which was also mentioned (obliquely) in OP's post — but with an actual benchmark where you can see why it matters. https://quuxplusone.github.io/blog/2022/08/26/vector-pessimi... https://godbolt.org/z/e4jEcdfT9
The second one is much more interesting, because it shows where `noexcept` can actually have an effect on codegen in the core language. TLDR, it can matter on functions that the compiler can't inline, such as when crossing ABI boundaries or when (as in this case) it's an indirect call through a function pointer. https://quuxplusone.github.io/blog/2022/07/30/type-erased-in...
About 10 days later the author wrote an article entitled noexcept affects libstdc++'s unordered_set. I had some concern that this keyword may impact performance in other STL containers and the author has provided a benchmark which proves such a case. I thank them for that. Vector Pessimization was something I wasn't aware about and does seem like a fairly advanced topic; which isn't apparent at the surface level of C++. I recommend you go and read their posts.