Update Feb. 21st, 2022: I recently added a Qt/QML based UI for PSRayTracing. It runs on Windows, Mac, Linux, Android, and iOS! Though if you have an Android device handy, you can grab it off of the Google Play store. Here's also a follow up blog post detailing the process.
![]()
Update Oct. 23rd, 2023: It's now on on the Apple App Store too now if you want it:
Note: If you want to look at this project's code, as well as the REAMDE which details the optimizations, you can find that here. This blog post moreso covers the process that I went through while working on this project. You could think of this as a post-mortem report, but I view it also as a guide for how to get more out of your CPU from your C++ program.
Extra thanks to Mr. Shriley for giving this post a proof read.
Right when I was fresh out of college, I was in the depth of my "Nim binge". I was looking to try a second attempt at writing a ray tracer after my so-so attempt back in a Global Illumination class. After a quick search on Amazon for "ray tracing" I found the Peter Shirley "Ray Tracing in one Weekend", "... The Next Week", and "... The Rest of your Life" mini books. At $3 a pop I thought it was a fair thing to take a look at. As an exercise to better learn the Nim language, I went through these books but used Nim instead of C++. Looking back at my first review of the book series, I feel as if I sounded a little harsh, but I really did have a pleasant time. I had some high hopes that my Nim version was going to perform faster than the book's code though it didn't. In fact, book no. 2 was much more woefully slow than the reference C++.
Now throughout the past 4-ish years, I've been seeing pictures from this book pop up here and there. Especially book 1's final scene. These books are now free to read online. I kind of now know what it feels like to purchase a game at release, only to see it go free-to-play a short while later. I think it's good that this introductory resource is now available to all. The HTML format is much better than the Kindle eBook in my opinion.
With the popularity of ray tracing exploding recently (thanks to hardware acceleration) I've only run across this book even more! A few months back I was itching to start a CG project. So I thought to myself "Why don't I revisit those ray tracing books, but this time do it in C++ 17. And try to optimize it as much as possible? Let's see if I can beat the book this time!" I chose this because I have been a little lax on learning the new(ish) C++17 features. I also wanted to see how far I could push a CPU bound renderer.
Here were some goals & restraints:
- Write modern, clean, standard C++ 17 code
- Needs to compile on Windows, Mac & Linux, under GCC & Clang
- Should be as vanilla as possible
- Two exceptions are single-header/static libraries (e.g PCG32), and one Boost library. Single header libs typically are pure C++ themselves and Boost is a defacto standard library for C++ anyways
- Give the code a nice, cleaner project architecture
- The books' original project structure is kinda messy to be honest
- I still have the keep the general architecture of the ray tracing operations itself, but I'm free to rename and re-organize things as I see fit
- Have it perform better than the books' implementation
- But add compilation (or runtime flags) to compare the book's methods with my own
- Add some extra features to the ray tracer
- Be able to reproduce every scene in the book, and deterministically
- Mutli-threading provided by
std::thread - I wasn't allowed to add any new rendering techniques that were beyond the scope of the book. E.g. No adaptive sampling. Threading is allowed since I can turn it off, as to compare the performance of my code vs. the books'. It's not really fair to compare Adaptive sampling vs. No adaptive sampling.
Books 1 & 2: Ray Tracing in One Weekend, and The Next Week
Revision 1
Setting out, it was pretty simple what I would do here. Read a section of the book, copy over the code, see if it worked, then continue on if so. While going through each section I would try to consider if there was a more performant way that the code could be written. Sometimes this would involve simply reordering lines of code, so that the compiler could do auto-vectorization. Other times, I would ponder if there was a more efficient algorithm.
A simple to follow example here would be the alternative *Rect::hit() methods (take XYRect::hit() for reference, the Book's code has this structure:
- Do Math (part A)
- Branch if A's math is bad (by doing math to check if so)
- Do more math (part B)
- Branch if B's math is bad
- Do even more math (part C)
- Store results (part C) in variables
If you want to speed up your program, one of the best ways to do this is reducing the number of branches. Try to put similar sections together. My code has the following structure for the hit() method:
- Do Math (parts A, B, & C together)
- Branch if math is bad (either A or B)
- Store the computed math (from C) if it's good
Compilers are pretty good at recognizing parts of your code that could benefit from auto vectorization. But putting all of the math operations together in one section gives the compiler better hints on how to solve these tasks much more efficiently. Reducing the possibilities of branches also helps as well.
Another great example of this comes from the AABB::hit(). The books' solution is chock-full with branches. The method I used (not 100% my own creation) eliminates the vast majority of the branching and keeps similar computations close together so that auto-vectorization can be achieved.
If you think you have something that's faster, the best way is to prove it is by measuring. And the best way to test this is by setting up a long render (e.g. 5 minutes). Don't forget to run it a few times, in order to make sure the renders complete within the same general time frame (with five minutes, it's okay to be off by a second or two). After that, you swap your changes and see if it shaves off a significant portion; which must be consistent through multiple runs.
Sometimes performance boosts from these ways could be quite significant (e.g. 8-15%), other times, they could be really-really tiny (e.g. 1-2%). For example, if you shave 10 seconds off of a 5 minute render time, that's only 3%. It can be a little difficult to conclude if a change truly saves on rendering time. So then that usually involves doing renders that would normally take upwards of 30 minutes, only to see if you still get that 3% render time improvement. You need to make sure that your computer is not running any other processes at the same time too.
And another important method of testing is to also verify any code changes on different hardware too. For example, sometimes on a Gen 7 Intel chip I would get a 30% speedup! But then on Gen 9 it was only 10% (still good). Then on a Gen 10 would maybe give me only mere 2%; I'd still take that.
I had a few optimizations that were in the ~1% area. These are the hardest to prove if there was any actual change on the rendering performance or not. This is where things start to get into the microbenching realm. It gets much more difficult to measure accurately. Environmental conditions can even start to affect measurements. I'm not talking about what operating system you're running on, but the actual temperature of your hardware. This page gives good detail on the relationship between heat and speed. Another way to test any micro optimizations is by taking the 1% changes and trying them out together. See if the sum of their parts makes a significant boost.
While running after all of these little improvements, I was reminded of Nicholas Omrod's 2016 CppCon presentation about small string optimizations at Facebook. After a lot of work, they were able to get a custom std::string implementation that was 1% more efficient. For them, that can be a very big deal. Though to your average company, that might not be so enthralling to spend time on. I can't remember the exact words, but some other wisdom was given in that talk: "For every small change we make, it adds up; and eventually, we make a big leap."
A very important tool that I cannot forget to mention is Matt Godbolt's Compiler Explorer. Those of you in C++ circles have definitely seen this before. For those of you outside of them, this tool lets you look at the generated assembly code for any given C/C++ snippet. With this, you can see if any C++ code rewriting/reordering would generate more efficient CPU code. The compiler explorer can also help you search for micro optimizations. Which as stated before, can be a little hard to measure with purely time lapping alone. I used the compiler explorer to see if there was a way to rewrite code that would reduce branching, use vectorized instructions or even reduce the amount of generated assembly.
I do want to note that in general reducing the amount of instructions a program has to run through doesn't always mean that it will run faster. For example, take a loop that has 100 iterations. If it were to be unrolled by the compiler, it would generate more assembly in the final executable. That unrolled loop will run faster since the loop no longer needs to check 100 times if the iteration is done. This is why we always measure our code changes!
One of the other key problems here was ensuring that my renders were always deterministic. Meaning, given the same inputs (resolution, samples-per-pixel, scene setup, etc.), the output render should be exactly the same. If I re-rendered with more or less cores, it should be the same as well.
The RNG controls where a Ray is shot. When the ray hits an object it could be bounced into millions of directions. Maybe 1/2 those possibilities will send the ray into the sky (where next to no objects are), and the other half could send it into a hall of mirrors filled with diamonds (an unlimited no. of bounces). A small tweak in the RNG could bias it (ever so slightly) into one of those areas more than the other. And if the hall of mirrors scene was set up by another RNG, any changes to that will also change the scene quite a bit, thus also changing the render time.
For example, the final scene of book 2 had three components that rely on the RNG. The floor (a bunch of boxes of varying heights), a "cloud" of spheres, and the BVH node structure. I tested out an optimization for the Box object that required the RNG. Rendering the cornell box example was about 6% faster. But when rendering out the aforementioned final scene it was 15% slower... I noticed that all of the floor boxes and "sphere cloud" were placed differently with the optimization on/off. At first I thought that couldn't be the issue. But when I used two separate RNGs (one for controlling the layout of the scene, the other for the Box optimization). Not only did I get back my original scene layout, I also got that perf boost I saw from the Cornell Box scene.
![Final Scene (book 2) [seed = ASDF]](https://storage.googleapis.com/sixteenbpp/blog/images/psraytracing-retrospective/render_final2_seed-ASDF.png)
![Final Scene (book 2) [seed = 0123456789]](https://storage.googleapis.com/sixteenbpp/blog/images/psraytracing-retrospective/render_final2_seed-0123456789.png)
Let's take two different renders of that final scene, but for the first image, I set the RNG to be "ASDF" and for the second it's "0123456789". These were rendered a few times over (to get a good average). The above rendered in an average of 973.0 seconds. The lower took an average of 1021.1 seconds. While that not seem like much, changing the RNG's seed made it render 5% slower!
I tried to make it when toggling on/off my optimizations, the resulting images would be the same. But there are some cases in which this ideal was bent a little. To be more specific, I'm talking about the trig approximations. If you're making a flight control system or a spacecraft, you want to be damn sure that all of your mathematical formulas are correct; but when it comes to graphics, we can fudge things if they fool the user. A.k.a the "eh... looks good enough" guideline.
Another good example here is that of the approximations for asin() and atan2(). For texturing spheres, the difference is barely noticeable, but the speed boost was impactful. It's very unlikely that without a comparison that flips between the two images quickly, no one would notice the difference! Though if we were to have a much higher detailed texture, and be zoomed in much closer to any of the trouble points (e.g having only the UK & Ireland in view), it's more likely a viewer might see something odd.
![Earth [ground truth]](https://storage.googleapis.com/sixteenbpp/blog/images/psraytracing-retrospective/earth_ground_truth.jpeg)
![Earth [ground truth]](https://storage.googleapis.com/sixteenbpp/blog/images/psraytracing-retrospective/earth_approx_with_ec.jpeg)
While the approximation optimization doesn't produce the exact same image. I guarantee you if you showed one of these renders to a person for a minute, told them to look away, then showed them the other, they would tell you it's the exact same picture. If you can get a faster render and don't need it to be mathematically accurate, approximations are great!
Not all attempts at trying to squeeze more performance were successful. I'm sure a lot of us have heard about the famous fast inverse square root trick that was used in Quake. I was wondering if there was something similar for computing the non-inverse version, std::sqrt(). The best resource that I found on the subject was this. After exhausting all of the methods presented, they either produced a bad image, or were actually slower than std::sqrt().

Revision 1 (or as it's tagged in the repo, r1) was where most of the work was done in this project. There were other possibilities I wanted to explore, but didn't have the time initially, so I delegated these to later releases. They aren't as grand as this initial one, but each of them has their own notes of significance.
Revision 2
While I was initially working on the Box object, I couldn't help but think that using six rectangles objects stored in a HittableList wasn't the most efficient way of rendering such an object. My initial optimization was to use a BVHNode instead (which also required an RNG). While that led to a reduction in rendering time, I felt that this could be pushed further. Looking at the hit() functions for each constituent rectangle, It seemed they could be put together in one grander function. This would have some benefits:
- Reduced memory overhead of creating seven extra objects. Which also means less memory traversing (or pointer chasing)
- Don't need to traverse a list (or tree) to find out what hit
- The code to check for hits looks like it could be easily auto-vectorized and have reduced branching
I don't want to bore you with the gory details ( you can see them here). This alternative Box::hit() function, it's quite SIMD friendly. From some of my measuring, this method was about 40% faster to render than the books' method!
Revision 3
At this point, I was starting to exhaust most of the "under the hood" optimizations that I thought could make an impact. Two more I explored this time around were "Deep Copy Per Thread" and "BVH Tree as a List".
Talking about that first one, this optimization was only available because my implementation allowed for rendering with multiple cores (the books' code does not). The scene to render is stored as a tree structure, filled with shared pointers to other shared pointers to even more shared pointers. This can be very slow if we're only reading data from the tree; which is what happens during the rendering process. My hypothesis was "For each thread I render with, if I make a local copy of the scene tree to that thread, the render will finish faster".
I added an extra method to each object/material/texture called deep_copy(), which would well, produce a deep copy of the object and its children. This was quite a bit of a tedious task. But when, for example, doing a render with 4x cores. Having "copy per thread" turned on, it would render the scene 20-30% faster! I'll admit I'm not 100% sure why this was so beneficial. I posed the question to one of Reddit's C++ communities, but I have yet to be given a satisfactory answer.
"BVH Tree as a List" was more of a complex experiment. While it was slightly more performant, it did not yield the results that I hoped for. The BVHNode class is nothing more than a simple object that may contain either another hittabale object, or two child BVHNodes. These are all stored with shared pointers. I was concerned that (reference counted) pointer chasing and fragmented (dynamic) memory might not be too efficient.
My thought was "If I take all of the AABB's for each node, and store them linearly in an array (i.e. list), but in such a way they can be traversed as a tree, this would allow for faster traversal". The hope was that it would be more memory/cache friendly to check all of the AABBs, rather than testing a chain of BVHNodes. The speedup was quite piddly; I measured about 1-2%. The code is much more convoluted than the standard BVHNode. If you wish to read it, it's here (don't forget to check out the header file too!)
At this point, I thought I had hit a limit on what I could change without breaking the architecture. I was looking to work on the implementation for book 3, but I decided it might be best to take a little break.
Revision 4
As I mentioned before, this mini-book series has exploded in popularity. Reading Peter Shirley's Twitter, I saw him retweeting images of a project called RayRender; a ray tracer for the R programming language that's useful for data-viz. This ray tracing program was actually based off of these mini-books. After that, I subscribed to Tyler Morgan-Wall's Twitter. In part, watching his progress made me interested in revisiting these books.
In a Christmas Eve tweet, he said that he was able to give RayRender a 20% performance boost. My curiosity was piqued and I started to scour through his recent commits.
For the HitRecord class, he simply changed a shared pointer over to being a raw pointer. That was all. HitRecord and its material pointer member are used a lot during the rendering process. It really makes no sense for them to be shared pointers at all. This little change netted me a 10% - 30% perf. boost! This one I'm a little upset about not realizing myself.
Book 3: Ray Tracing the Rest of Your Life
Before working on r2 I tried to make an attempt at book 3. But while working through its initial chapters, I soon realized it was impossible to make sure I could render any older scenes. This was because the core logic of the main rendering function was changing quite a bit from chapter to chapter.
But in the interest of completeness (and that I exhausted all other possible optimizations I could think of), I set out to finish the series. It's in a separate branch called book3. It can't render any of the older scenes from books 1 & 2.
Revision 5
There is nothing special about this revision. It's nothing more than book 3 alone. It only supports four scenes; the Cornell Box box with various configurations.
While I was working on it, I did encounter a "fun" rendering bug that was an absolute pain to figure out. I forgot to set an initial value for a variable. Take this as a good lesson on why you should always assign an initial value to anything.
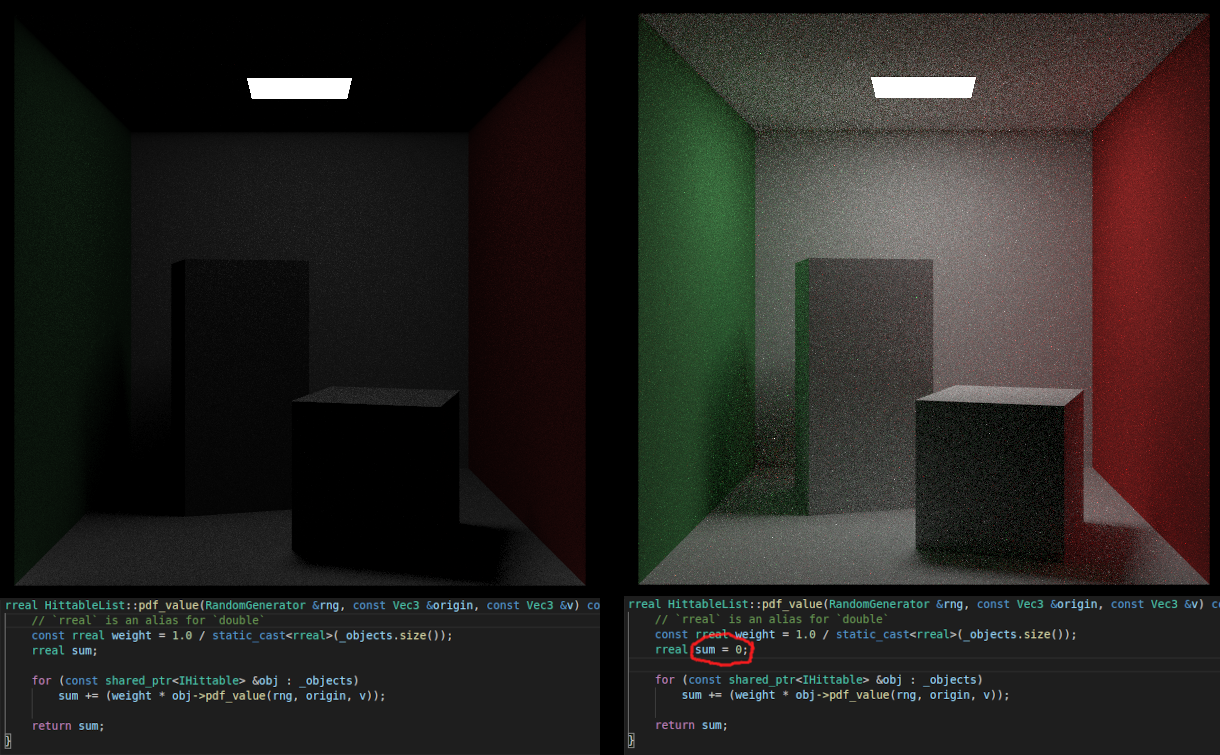
Revision 6
While going through Book 3, I couldn't help but notice that during the rendering stage, we allocate dynamic memory and pass it around with shared pointers; this is an absolute speed killer. This was being done for the PDFs. Taking a stern look at the code, it looked like the PDFs could be allocated as stack memory instead.
Part of the issue is that inside some of the objects' hit() functions, it could generate a PDF subclass of any time. But then that function had to return the PDF as a pointer to a base class. Then later on, the PDF would be evaluated with virtual functions; value() and generate().
So I thought "Wouldn't it be possible to pass around PDFs using a variant?" One of the rules for variants is that they must be allocated on the stack. This solves the issue of dynamic memory (and usage of shared pointers). Then when we need to evaluate the PDF, the variant can tell us exactly which specific PDF to use, and thus the appropriate value() and generate(). Therefore, PDFVariant was born. Any of the existing PDF subclasses can be put into it.
The code for this is on another separate branch called book3.PDF_pointer_alternative. This also breaks the architecture a little. MixturePDF was a little bit of an issue since it originally required two shared pointers to PDFs. Replacing PDFVariant for those pointers doesn't not work, so I needed to use raw pointers to PDFs instead.
Final Thoughts
It was a really great experience to re-explore this book series, as well as Ray Tracing. There are other optimizations I think that could push the performance much further, but these all would require breaking architecture more than I already have. Just some ideas:
- Remove all uses of shared pointers and use raw ones instead
- Incorporate libraries like Halide so some parts could be run on the GPU (breaks my "CPU-only" rule though)
- Incorporate other sampling methods; e.g. blue-noise or sobol
- See if rendering could be performed "breath first" instead of "depth first"
When I first went through the book series four years ago, there were bits of errata here and there. I made sure to email Mr. Shirley whatever I found. I think all of them have been cleaned up. But since this book series is now freely available online and a community project, some more have been introduced; I recall finding more in book 3 than others.
There are some other things I find a little unsatisfactory too:
- Having to throw away all of the other scenes from books 1 & 2 to do book 3. It would be fun to revisit those former scenes with PDF based rendering
- Rotations are only done along the Y axis, and there is no way to change the point an object is rotated about. Though, anyone who wants to add this for the X & Z axis should be able to easily do so. Maybe in a future revision of this book having the rotation method use quaternions instead
- The Motion Blur effect feels wrong. Only spheres can be motion blurred. And for the feature, we had to give Rays a sense of time
But keep in mind the ray tracer that is built more on the educational side rather than being more "real world application" focused. It serves the purpose of teaching well. I still recommend that anyone who is interested in computer graphics give this book a read through.
There are other parts of CG programming I want to explore; I think it's a good time to move on.