Update February 16th, 2025: I've posted this article on a few places, and if you've read the comments sections (such as on /r/cpp), it's well mentioned that this was very poorly titled. I would like to acknowledge this fact. The title was not my number one priority when writing this post; the content was. With this said, I'm not going to be changing anything below.
1. I'd need to change many URLs and possibly break linkage to this. That's a lot of work
2. We all goof up at times. I don't want to hide this and would like to show to our more junior developers that your seniors will make mistakes as well
3. /u/STL was generous enough to bestow a custom post flair on the article
Those aren't handed out to just anyone. You have to work for that, and hard.
In the realm of computer science, we're always told to pursue what is the most efficient solution. This can be either what is the fastest way to solve a problem; or what may be the cheapest.
What is the easiest, but not always the best, is typically a "greedy algorithm"; think bubble sort. More often than not, there is a much more efficient method which typically involves thinking about the problem a bit deeper. These are often the analytical solutions.
Whilst working on PSRayTracing (PSRT), I was constantly finding inefficient algorithms and data structures. There are places where it was obvious to improve something, whereas other sections really needed a hard look-at to see if there was more performance that could be squeezed out. After the podcast interview I was looking for the next topic to cover. Scanning over older code, I looked at the random number generator since it's used quite a bit. I spotted an infinite loop and thought "there has to be something better".
The code in question is a method to generate a 2D (or 3D) vector, which falls within a unit circle (or sphere). This is the algorithm that the book originally gave us:
Vec3 get_in_unit_disk() {
while (true) {
const Vec3 p(get_real(-1, 1), get_real(-1, 1), 0);
if (p.length_squared() >= 1)
continue;
return p;
}
}
The above in a nutshell:
- Generate two (random) numbers between
[-1.0, 1.0]to make a (2D) vector - If the length squared of the vector is
1or greater, do step 1 again - If not, then you have a vector that's within the unit circle
(The 3D case is covered by generating three numbers at step 1)
This algorithm didn't feel right to me. It has some of that yucky stuff we hate: infinite looping and try-and-see-if-it-works logic. This could easily lead to branch prediction misses, being stuck (theoretically) spinning forever, wasting our random numbers. And it doesn't feel "mathematically elegant".
My code had some commented out blocks with an analytical solution to the above. But in the years prior when I had first touched that code I had left a note saying that it was a bit slower than using the loop.
The next day I had an email fall into my inbox. It was from GitHub notifying me of a response. The body was about how to generate a random point inside of a unit sphere... Following the link to the discussion, it came from the original book's repository. The first reply in 4 years on a topic... that... I... created...
I think this was a sign from above to investigate it again.
Reading through the old discussion (please don't look I'm embarrassed), one of the maintainers @hollasch left a good comment:

What really stuck out to me is in the beginning:
"The current approach is significantly faster in almost all cases than any analytical method so far proposed ... every time our random sampling returns an answer faster than the analytical approach,"
Are rejection methods much faster than an analytical solution? Huh.
Understanding The Problem A Little More
As seen above, there is an analytical solution to the above algorithm for both the 2D and 3D cases. We'll use Python for the moment.
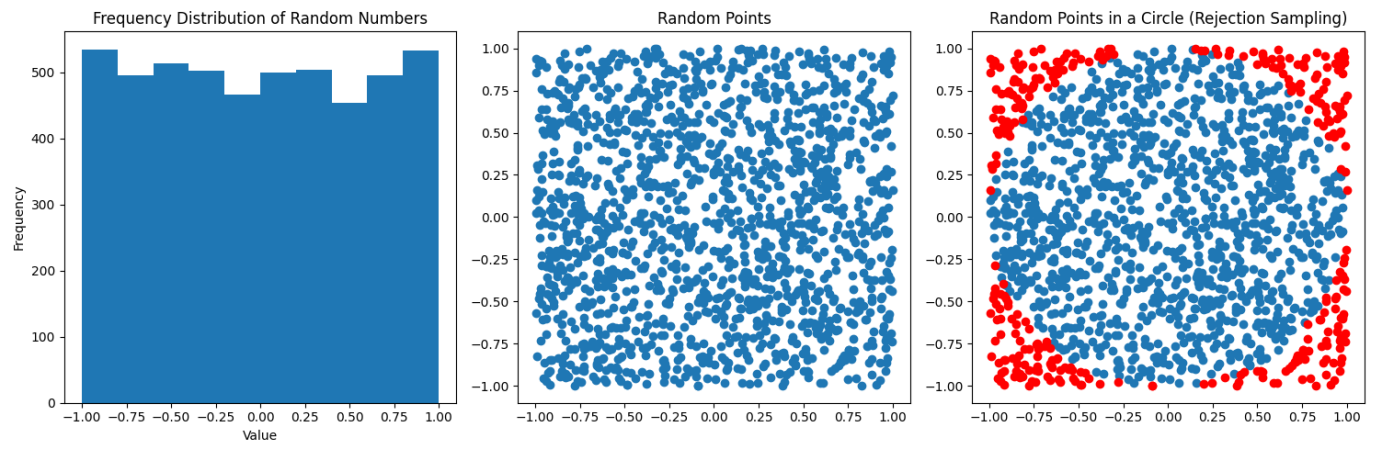
In the above diagrams, we're just taking a random sampling of points inside a 2D plane. You can see they are fairly uniformly distributed. To the far right the points in blue are what falls within the unit circle, the red is what falls outside (and we must throw out). In a nutshell this is a visualization of the rejection sampling method:
def rejection_in_unit_disk():
while True:
x = random.uniform(-1, 1)
y = random.uniform(-1, 1)
v = Vec2(x, y)
if (v.length_squared() < 1):
return v
Using the area formulas for a square and a circle, we can find out the chance that a point will fall inside the circle:
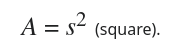
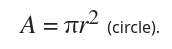
In this case, r = s / 2, and it's <circle area> / <square area>. If you do all of the math, you'll find that the odds are ~78.54%. Which means that around 22% of our points are rejected; that isn't desirable.
For the analytical solution, you have to think in terms of polar coordinates: Generate a random radius and generate a random angle. Initially you might assume the correct method is this:
def analytical_in_unit_disk_incorrect(): r = random.uniform(0, 1) theta = random.uniform(0, two_pi) x = r * math.cos(theta) y = r * math.sin(theta) return Vec2(x, y)
But that's not quite right:
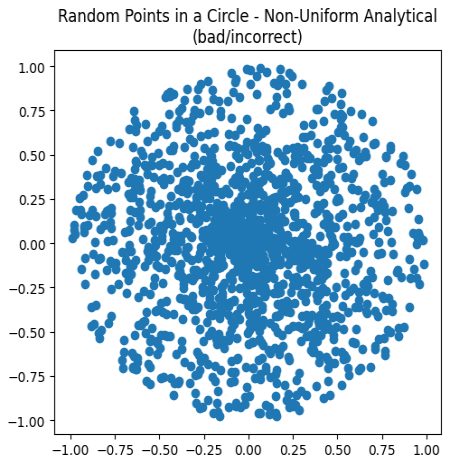
Charting these points, while all are falling within the unit circle, they are clustering more in the center. This is not correct. We need to alter the distribution of the points to appear more uniform. Remember from math class how you needed to use a square root to calculate the distance of a vector? That's also the trick to fixing the scattering:
def analytical_in_unit_disk(): r = math.sqrt(random.uniform(0, 1)) theta = random.uniform(0, two_pi) x = r * math.cos(theta) y = r * math.sin(theta) return Vec2(x, y)
Huzzah! We now have the analytical solution:
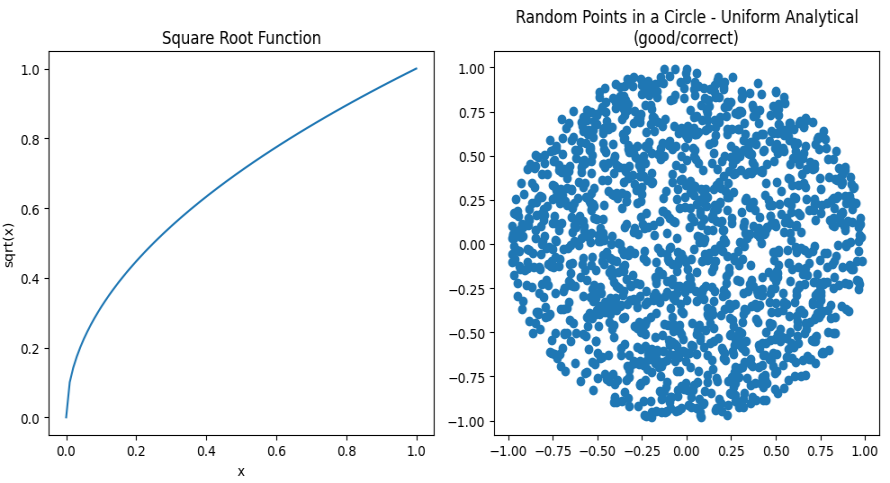
Look at how beautiful that is:
- All points fall within the unit circle
- All look to be equally distributed
- No (theoretical) infinite looping
- No wasted random numbers
The 3D case the rejection method is the same (but you add an extra Z-axis).
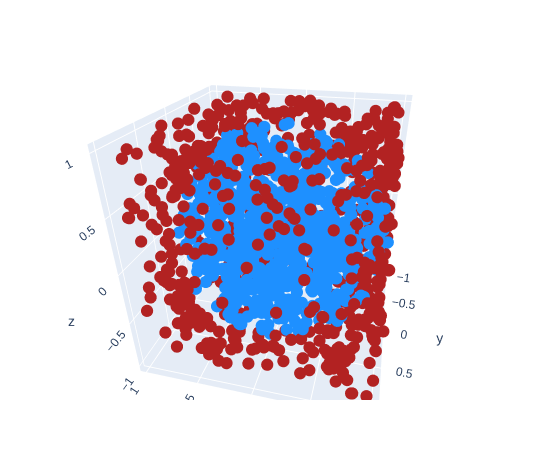
How much more inefficient is the rejection sampling in 3D? It's way worse than the 2D case. Take these volume formulas. The first being that of a cube's and the second that of a sphere's.
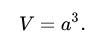
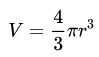
Similarly, when a = r / 2, the chance a randomly generated point (using rejection sampling) falls within the sphere, is only 52.36%. You have to throw out nearly half of your points!
The analytical (spherical) method is a tad more complex, but it follows the same logic. If you want to read more about this, Karthik Karanth wrote an excellent article. The Python code for the 3D analytical solution is as follows:
def analytical_in_unit_sphere(): r = math.cbrt(random.uniform(0, 1)) theta = random.uniform(0, two_pi) phi = math.acos(random.uniform(-1, 1)) sin_theta = math.sin(theta) cos_theta = math.cos(theta) sin_phi = math.sin(phi) cos_phi = math.cos(phi) x = r * sin_phi * cos_theta y = r * sin_phi * sin_theta z = r * cos_phi return Vec3(x, y, z)
Jumping ahead in time just a little, let me show you the same scene rendered twice over, but with each different sampling method:


The one on the left was using boring rejection sampling, whereas the one on the right is using this new fancy analytical method. At a first glance the two images are indistinguishable; we'd call this "perceptually the same". Zooming in on a 32x32 patch of pixels (in the same location) you can start to spot some differences. This is because we are now traversing through our random number generator differently with these two methods. It alters the fuzz, but for the end user it is the same image.
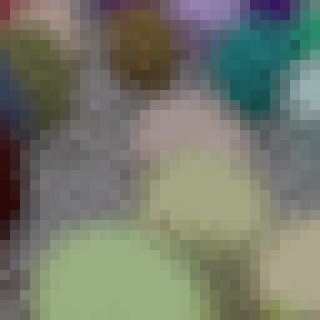
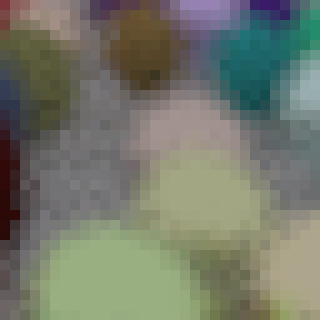
(Hint: look at the top two rows, especially the purple near the right side)
Benchmarking (Part 1)
Let's stay in Python land for the moment because it's easier. We can create a small benchmark to see how long it takes to generate both the 2D & 3D points. The full source code of the program can be found here. The critical section is this:
# Returns how many seconds it took
def measure(rng_seed, num_points, method):
bucket = [None] * num_points # preallocate space
random.seed(rng_seed)
start_time = time.time()
for i in range(0, num_points):
bucket[i] = method()
end_time = time.time()
return (end_time - start_time)
def main():
rng_seed = 1337
num_runs = 500
num_points = 1000000
# ...
for i in range(0, num_runs):
seed = rng_seed + i
r2d = measure(seed, num_points, rejection_in_unit_disk)
a2d = measure(seed, num_points, analytical_in_unit_disk)
r3d = measure(seed, num_points, rejection_in_unit_sphere)
a3d = measure(seed, num_points, analytical_in_unit_sphere)
# ...
From there we can take measurements of how long each method took and compare them. Running on a 10th Gen i7 (under Linux), this is the final runtime of the benchmark:
Rejection 2D: Mean: 0.893 s Median: 0.893 s Analytical 2D: Mean: 0.785 s Median: 0.786 s Rejection 3D: Mean: 1.559 s Median: 1.560 s Analytical 3D: Mean: 1.151 s Median: 1.150 s
Looking at the median rejection sampling is 13% slower in the 2D case and 35% in the 3D case!! Surely, we must now use the analytical method. All of this work we've done was definitely worth it!
Taking It Into The Ray Tracer
Placing the analytical methods into the ray tracer was very trivial. All of the math functions exist in the standard library therefore the port from Python is nearly 1-1 one to one. Here's how long it takes to the render the default scene with the sad-poor rejection sampling:
{kind=link}
me@machine:$ ./PSRayTracing -j 4 -n 500 -o with_rejection.png ... Render took 105.956 seconds
And now, recompiled with our Supreme analytical method:
me@machine:$ ./PSRayTracing -j 4 -n 500 -o with_analytical.png ... Render took 118.408 seconds
(These measurements were taken with the same 10th Gen i7 on Linux compiled with GCC 14 using CMake's Release mode.)
Wait, it took longer to use the analytical method? Inspecting both renders they are perceptually the same. Pixel for pixel there are differences, but this is expected because the random number generator is being used differently now.
{kind=link}
{kind=link}
Just like my note from 4 years ago said... It's... Slower... Something Ain't Right.
Benchmarking (Part 2)
We need to dig in a little more here. Let's benchmark the four methods separate from the ray tracer again, but this time in C++. If you want to read the source, I'll leave the link right here: comparing_greedy_vs_analytical.cpp . It's structured a tiny bit different from the Python code, but we have as little overhead as possible. We'll also be using the same RNG engine, the Mersenne Twister (MT).
I want to take an aside here to mention that PSRT actually uses PCG by default for random number generation. It's much more performant than the built in MT engine and doesn't get exhausted as quickly. I wrote about it briefly before. The MT engine can be swapped back in if so desired. While any random number generation method can greatly impact performance, in this case it is not the cause of the slowdown seen above.
me@machine:$ g++ comparing_greedy_vs_analytical.cpp -o test ./test 1337 500 1000000 Testing with 1000000 points, 500 times... run_number: rejection_2d_ms, analytical_2d_ms, rejection_3d_ms, analytical_3d_ms 1: 516, 268, 658, 423, 2: 295, 273, 640, 428, ... 499: 306, 278, 670, 445, 500: 305, 279, 676, 446, mean: 313, 277, 675, 448 median: 305, 276, 665, 444 (all times measured are in milliseconds)
It's still showing the analytical method is still much more faster than the rejection sampling. About 10% for 2D and nearly 33% for 3D. Which is what is aligned with the Python benchmark. What could be going on here... Oh wait; Silly me...
I forgot to turn on compiler optimizations... Let's run this again now!
me@machine:$ g++ comparing_greedy_vs_analytical.cpp -o test -O3 ./test 1337 500 1000000 Testing with 1000000 points, 500 times... run_number: rejection_2d_ms, analytical_2d_ms, rejection_3d_ms, analytical_3d_ms 1: 87, 137, 96, 81, 2: 17, 33, 40, 80, ... 499: 18, 35, 42, 82, 500: 18, 35, 44, 82, mean: 20, 38, 44, 82 median: 17, 34, 42, 82 (all times measured are in milliseconds)
What-
The rejection sampling methods are faster?! And by 50%?!!?!
This needs more investigation.
Benchmarking (Part 3)
If you've read the other posts in this series, you know that I like to test things on every possible permutation/combination that I can think of. At my disposal, I have:
- An Intel i7-1050H
- An AMD Ryzen 9 6900HX
- An Apple M1
With the x86_64 processors I can test GCC, clang, and MSVC. GCC+Clang on Linux and GCC+MSVC on Windows. For macOS we're playing with ARM processors so I only have Clang+GCC available. This gives us 10 different combinations of Chip+OS+Compiler to measure. But seeing above how optimizations levels affected the runtime we need to look at different compiler optimization flags (-O1, -Ofast, /Od, /Ox, etc). In total there are 48 cases which can be tested.
Turning on compiler optimizations can seem like a no-brainer but I need to mention there are risks involved. You might get away with -O3, but -Ofast can be considered dangerous in some cases. I've worked in some environments (e.g. medical devices) where code was shipped with -O0 explicitly turned on as to ensure there no unexpected side effects from optimization. But then again, we use IEEE 754 floats in our lives daily, where -1 == -1024. So does safety really even matter?
As a secondary side tangent: I do find MSVC's /O optimizations a bit on the confusing side. I come from the GCC cinematic universe where we have a trilogy (-O1, -O2, -O3), a prequel (-O0), and a spinoff (-Ofast). MSVC has the slew of /O1, /O2, /Ob, /Od, /Og, /Oi, /Os, /Ot, /Ox, /Oy which call all be mixed and matched as a choose-your-own-adventure novel series. This Stack Overflow post helped demystify it it for me.
Using the above C++ benchmark, the results have been placed into a Google Sheet. As always, they yield some fascinating results:
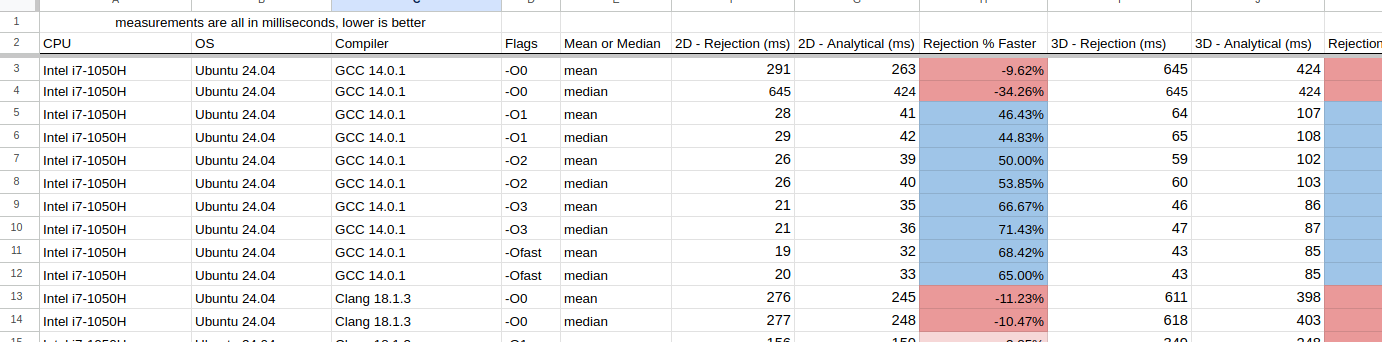
Normally, I would include some fancy charts and graphs here, but I found it very difficult to do so and I didn't want to cause any confusion. Instead there are some interesting observations I want to note:
- For Intel+Linux+GCC just turning on
-O1yielded significant improvements- On average, optimizations made rejection sampling 50% faster
- For Intel+Linux+Clang in nearly all of the cases, the analytical method was faster
- Especially for 3D
- The only exception was when
-Ofastwas used, the rejection sampling performed better
- For Intel+Windows+GCC rejection sampling was always better. Typically +150% for the 2D case, and +70% for 3D
- Intel+Windows+MSVC is comparable to the above (GCC) but was slower
- On AMD, all compilers on each OS behaved the same as on Intel
- With the M1 chip (macOS) GCC performed much better than clang
- Except for
-O0GCC's rejection sampling was always faster than the analytical method - Clang on the other hand, 2D rejection sampling was faster, but for the 3D case, using the analytical method was faster.
- Except for
This is a bit bonkers, as I really didn't expect there to be that much difference. Clang seemed to do better with analytical sampling, but GCC (with optimizations on) using rejection sampling stole the show. In general, I'm going to claim now that rejection sampling is better to use.
Assembly Inspection
I'm always iffy when it comes to inspecting the assembly. It's not my wheelhouse, and playing "count the instructions" is my favorite way of measuring performance; running code with a stopwatch is. If you need a basic primer on the topic, these two videos give a nice overview about some more of the important parts:
Reducing instruction counts, jumps and calls are what we aim for.
Taking a look at GCC 14.2's x86_64 output, the -O0 case is quite straightforward. We're going to only cover the 2D case as it's less to go through.
First up with rejection sampling (full code here), it will take around ~110 instructions to fully complete. Coupled with that we have 4 procedure calls and at the end a check to see if we need to repeat the entire process (and remember there is 22% chance it could happen). In the case we repeat it, then it would be around ~205 instructions (and 8 procedure calls).
In the analytical case (full code here) there's a little less than ~100 instructions to compute. Now on the flip-side there are 6 calls, but there is zero chance that we'll have to repeat anything in the procedure.
When cracking up that compiler to -O3, we have to throw everything above out the window as the assembly becomes very hard to decipher. I'll try my best, but if I'm wrong, someone who could contact me to correct it would be much appreciated
(Full code here) This is where I think the rejection method is in the code. This is because of the jne L16 line. A similar pattern of execution is viewed above for -O0. The compiler is optimizing away and inlining a bunch of other functions which makes this hard to track. Here, we have only 45 instructions to run, and not a single call!
(Full code here) This is my best guess of the -O3'd analytical method. The clue here for us is there are the two call instructions; one to sincos() and sqrt(). This looks to be about 55 instructions long, which already loses the counting competition. Coupled in with the calls this will definitely be slower.
Measuring the runtime of the code will always beat looking at assembly. The assembly can give you insights, but it's worthless in the face of a clock. And as you can see from turning on -O3 (or even -O1) it can be much harder to glean anything useful.
Benchmarking (Part 4)
Just because the smaller test case shows a 50%+ performance boost in some cases, that doesn't mean we'll see that same increase in the larger application. A benchmark of a small piece of code is meaningless until it's been placed into a larger application. If you've read the previous posts from this blog, this is where I like to do some exhaustive testing of the Ray Tracing code for hundreds of hours. 🫠🫠🫠
The testing methodology is simple:
- There are 20 scenes in the ray tracer
- We'll test each of them 50 times over with different parameters
- The same test will be run once with rejection sampling and once with the analytical method
- The difference in runtime will be written down
I need to note I turned on the use of the real trig functions this time. By default PSRT will use (slightly faster) trig approximations. But to better keep in line with the benchmark from above, 100% authentic-free-range-organic-gluten-free-locally-grown sin(), cos(), atan2(), etc() was used. You can read more about the approximations here.
After melting all of the CPUs available to me, here are the final results. Everything was compiled in (CMake's) Release mode, which should give us the fastest code possible (e.g. -O3):

In some cases, rejection sampling was faster, in others using the analytical method was. Visualizing the above as fancy bar charts:
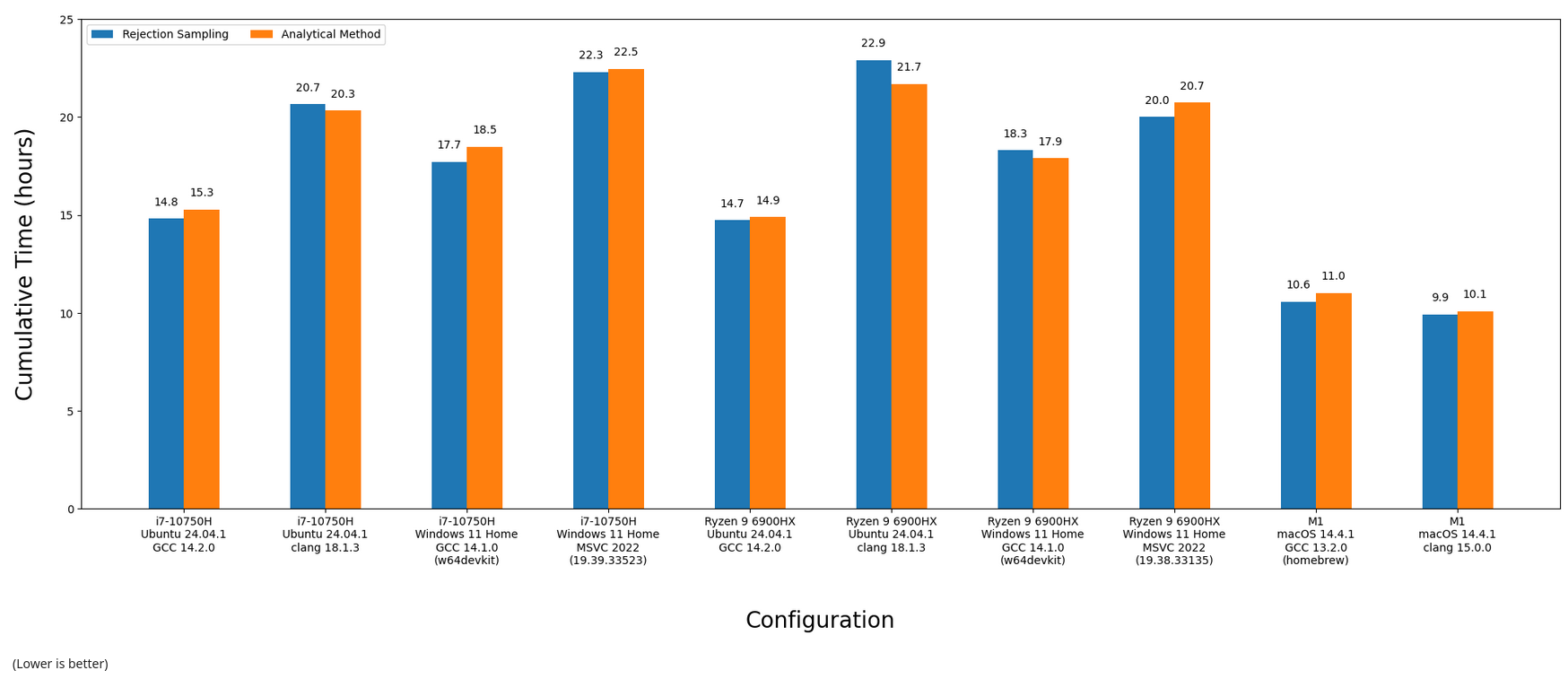
The scene by scene breakdown is more intriguing. Here's the means and medians for each scene vs. configuration:
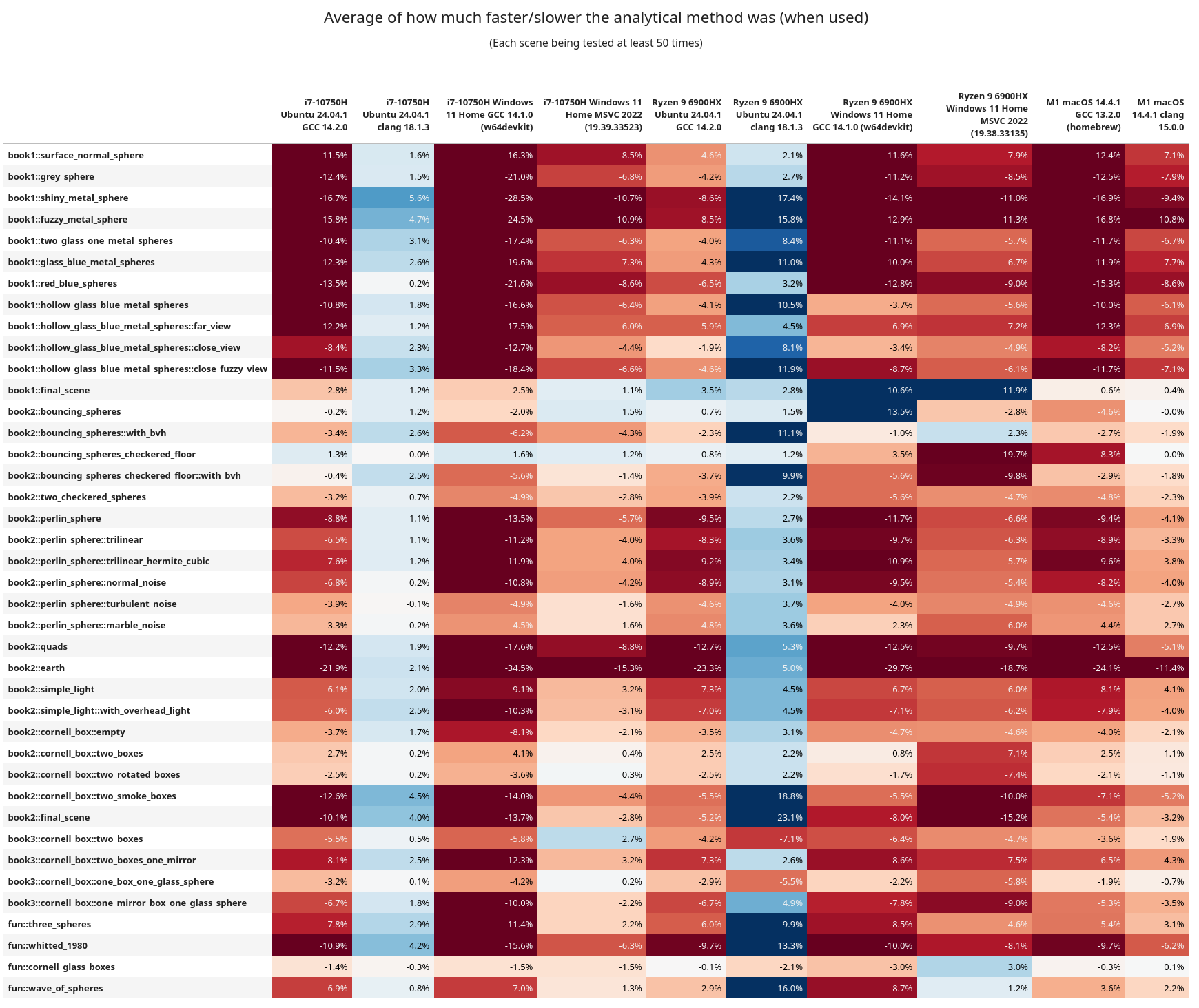
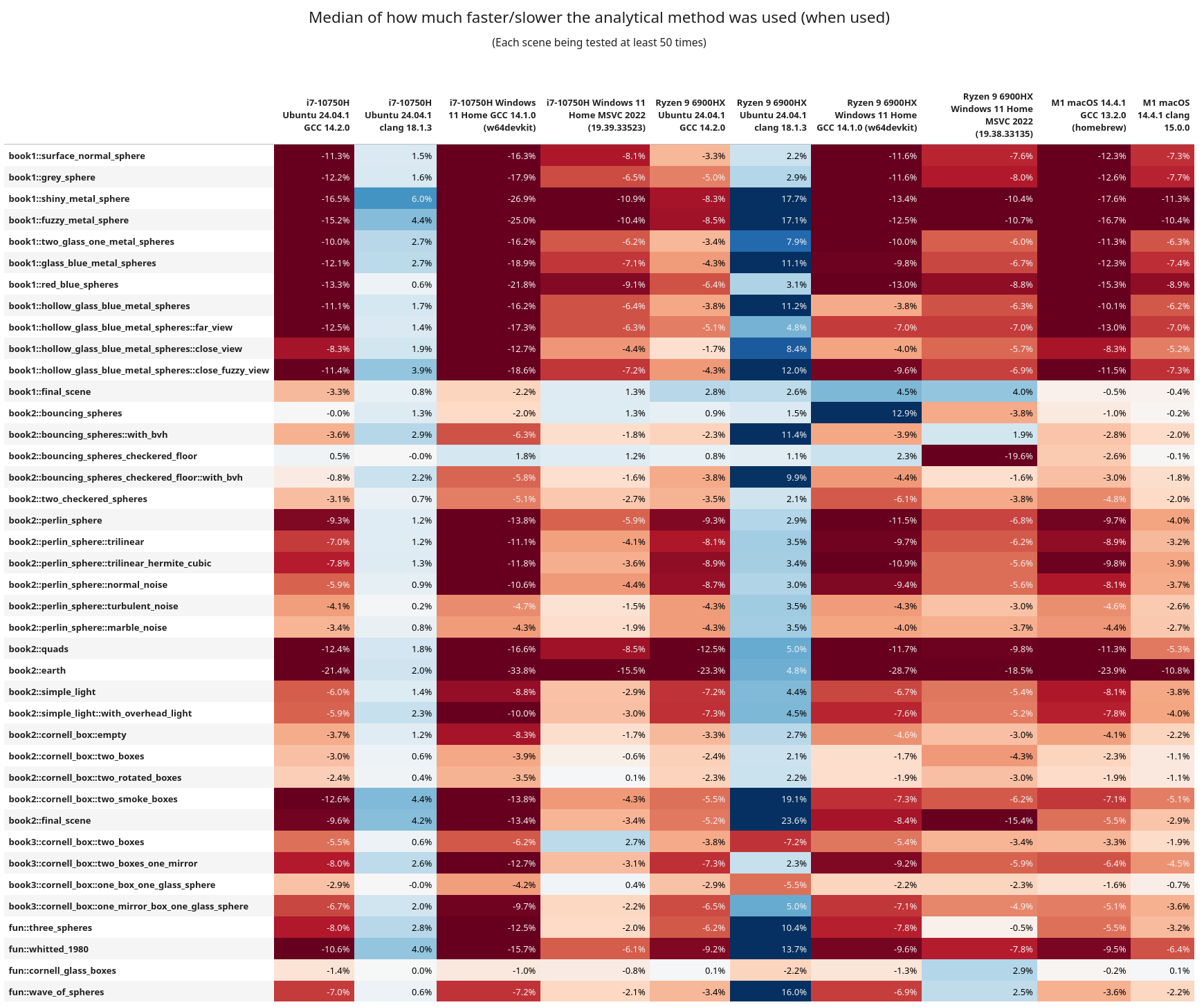
Here are some of the interesting observations:
- In general, rejection sampling is MUCH more performant, and sometimes by a wide margin
- Clang was having a better time on x86_64 when using the analytical method
- But keep in mind GCC is overall more performant, and with rejection sampling instead
book1::final_sceneandbook2::bouncing_sphereshave lots of elements in them, but are not using a BVH tree for ray traversal. Across the board rejection sampling isn't helping too much, and in fact the analytical method is more performant.- After them these scenes have a
with_bvhvariant (that does use the BVH tree) and they then see a benefit from rejection sampling.- When using analytical sampling the AMD chip isn't getting hit as hard on performance as the Intel one. This is more easily observed in the
book1scenes. Following these, all of the scenes now use a BVH tree - On Linux+GCC, Intel and AMD ran the entire test suite in approximately the same time, but AMD was every so slightly faster
- Linux+Clang ran better on Intel
- Intel+Windows+GCC had rejection faster, but AMD+Windows+GCC did better with analytical
- AMD ran the Windows+MSVC code significantly faster (by 2 hours!!)
- From the assembly inspection above, I wonder if maybe the AMD chips are better at running the
callinstruction? Or are better at running some of the math functions. This is wild guessing at this point. - I do want to note that these are chips from different generations, so it can be like comparing apples to oranges.
- When using analytical sampling the AMD chip isn't getting hit as hard on performance as the Intel one. This is more easily observed in the
If you want to see the variance from the above tables, it's here, but it's more boring to look at.
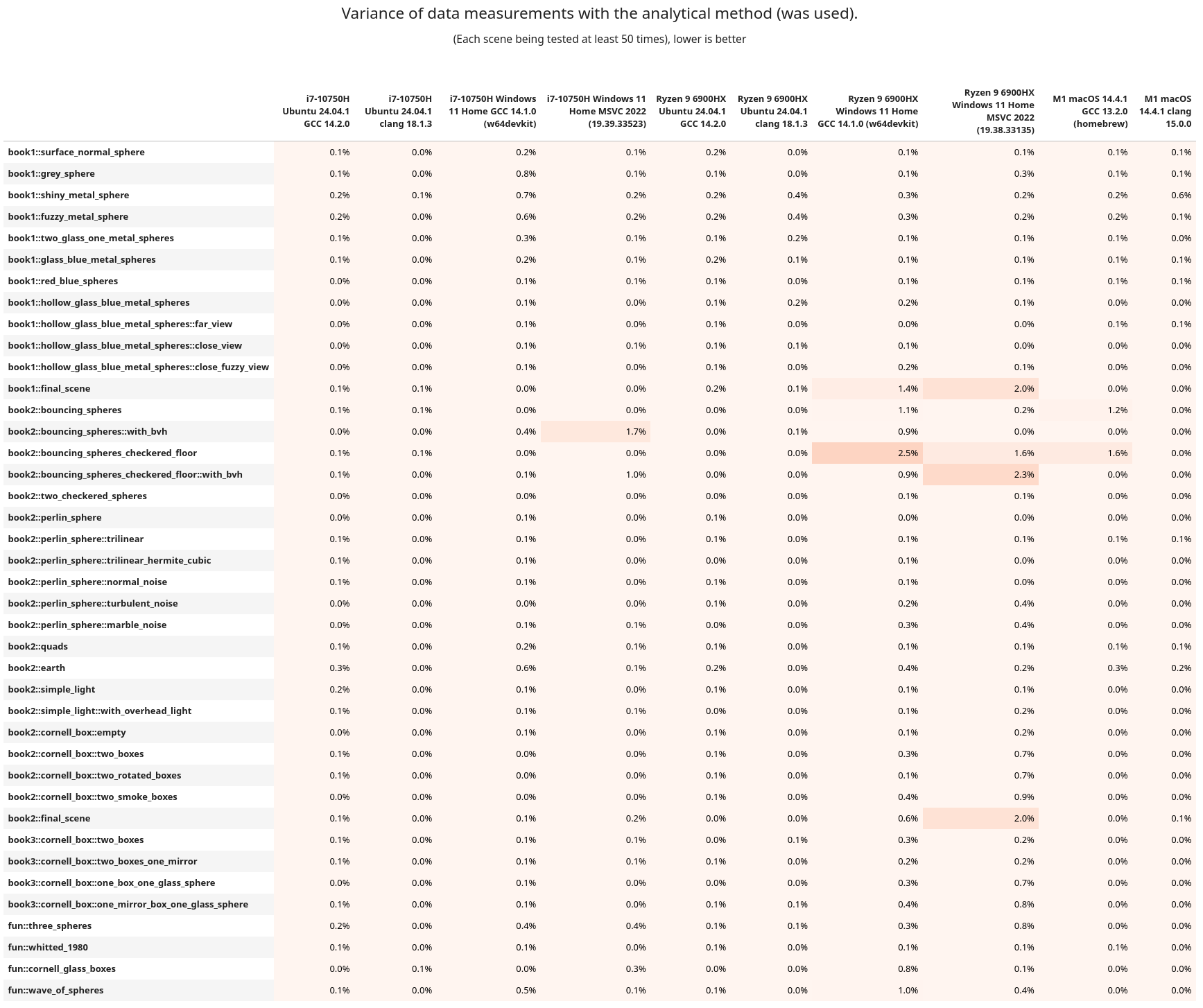{kind=link}
Benchmarking (Part 5)
While clang was slower than GCC, it was surprising to see that it actually had a performance benefit when running the analytical method. Seeing how Python also fared better with this method, I thought it might be worth seeing what happens elsewhere. Clang is built upon LLVM, So it's possible that this could have an effect on other languages of that lineage. Let's take a trip to the Rustbelt.
To keep things as simple as possible, we're going to port the smaller C++ benchmark (not PSRT). I've tried to keep it as one-to-one as possible too. The code is nothing special, so I'll link it right here if you wish to take a look. This is the first Rust program I have ever written; please be gentle.
Running on the same Intel & Linux machine as above (using rustc v1.83), Debug (no optimizations) reported that rejection was slower and the analytical faster:
Testing with 1000000 points, 500 runs... [rng_seed=1337] run number: rejection_2d_ms, analytical_2d_ms, rejection_3d_ms, analytical_3d_ms 1: 216, 202, 480, 344 2: 218, 206, 475, 344 ... 499: 210, 198, 454, 329 500: 209, 198, 454, 328 mean: 211, 199, 459, 332 median: 211, 199, 458, 331 (all times are measured in milliseconds)
And with Release turned on rejection was faster:
Testing with 1000000 points, 500 runs... [rng_seed=1337] run number: rejection_2d_ms, analytical_2d_ms, rejection_3d_ms, analytical_3d_ms 1: 24, 32, 49, 81 2: 19, 32, 44, 82 ... 499: 19, 32, 44, 82 500: 19, 32, 44, 81 mean: 19, 31, 43, 81 median: 19, 32, 44, 82 (all times are measured in milliseconds)
What's fun to note here is this Rust version is slightly faster than its C++/GCC equivalent. But when the same code is compiled with C++/Clang it doesn't do as well (check rows 11, 12, 21, & 22). I'm glad to see that Rust is exhibiting the same behavior as C++ with and without optimizations.
Closing Remarks
After all of this work, PSRT will stick with using the naive rejection sampling over the beautiful analytical method. It's frustrating to spend time on something you thought was the better way, only to find out that, well, it isn't.
If there is one main take away from this post: always test and measure your code. Never trust, only test. Unexpected things may happen, and results may change over time. It's the same thing I've been saying since the first article. And it bears repeating because not enough people do this. You can inspect assembly, reduce branches, get rid of loops, use faster RNGs, etc. But all of that can go out the window if runtime was never recorded and compared.
Remember, the compiler will always be smarter than you and optimizations are wizard magic that we don't deserve.

This past week I was invited onto CppCast (episode 389) to talk about some of the C++ language benchmarking I've been doing and about PSRayTracing a little bit too. I'd like to thank Phil Nash and Timur Doumler for having me on.
Over the course of working on PSRayTracing (PSRT), I've been trying to find all sorts of tricks and techniques to squeeze out more performance from this C++ project. Most of it tends to be alternative algorithms, code rewriting, and adjusting data structures. I thought sprinkling the final keyword like an all purpose seasoning around every class was "free performance gain". But... that didn't really turn out to be the case.
Back in the early days of this project (2020-2021), I recall hearing about the noexcept keyword for the first time. I was reading through Scott Meyer's works and picked up a copy of "Effective Modern C++" and watched a few CppCon talks about exceptions. I don't remember too much, but what I clearly recall:
- Exceptions are slow, don't use them
noexceptwill make your code faster
I re-picked up a copy of the aforementioned book whilst writing this. "Item 14: Declare functions noexcept if they won't emit exceptions" is the section that advocates for this keyword. Due to copyright, I cannot post any of the text here. Throughout the section the word "optimization" is used. But, it neglects any benchmark.
For those of you unfamiliar with noexcept, here is the nutshell explanation: you can use it to mark if a function will not throw an exception. This is useful for documentation and defining APIs. Personally, I really like that the keyword exists.
Similar to what I did for the final keyword, I created a NOEXCEPT macro that could be used to toggle on/off the use of noexcept at CMake configuration time. This way I could see by how much the keyword could improve throughput by.
When I did the initial A/B testing, I don't recall seeing that much of a speedup. The rendering code (which is what is measured) had zero exceptions from the start. PSRT does have a few, but they are all exclusively used in setup; not during any performance critical sections. I still left it in (and turned on) because it didn't seem to hurt anything and potentially help.
Back in April 2024 when I published that one article about my findings of final's performance impact, I submitted it to CppCast via email. Timur Doumler (one of the co-hosts) asked me if I had any performance benchmarks about the use of noexcept. I did not.
But since the time I first added in NOEXCEPT, I had created automated testing tools (which also tracks the performance) and an analysis suite to view the data. I decided to re-run all of the same tests (including more), but this time to truly see if noexcept actually does have some impact on performance.
The short answer is: yes, but also no; it's complicated and silly.

Prior Art
In his email, Mr. Doumler told me that no one else in the C++ community had yet to publish any benchmarks about the keyword; to see if it actually did help performance.
At first, I wasn't able to find any. But eventually I did stumble across a 2021 answer to a 2013 stack overflow question. vector::emplace_back() was found to be about 25-30% faster if noexcept was being used. Fairly significant! But this lacks telling us what CPU, OS, and Compiler were used.
In the 11th hour of writing this, I found a lighting talk from C++ on Sea 2019. Niels Dekker (while working on ITK) did his own version of the NOEXCEPT macro along with benchmarks. He is reporting some performance improvements, but his talk also said there are places where noexcept was negative. One other finding is that it was compiler dependent.
And, that's about it. From cursory Googling there is a lot of discussion but not many numbers from an actual benchmark. If any readers happen to have one on hand, please message me so I can update this section.
How Does noexcept Make Programs Faster?
This is something I had some trouble trying to figure out (and I don't seem to be the only one). An obvious answer could be "because it prevents you from using exceptions that slow down your code." But this isn't satisfactory.
Among performance minded folks, there is a lot of hate for exceptions. GCC has a compiler flag -fno-exceptions to forcibly turn off the feature. Some folks are trying to remedy the situation by providing alternatives. Boost itself has two: Outcome and LEAF. Right now LEAF seems to be winning in terms of speed.
Kate Gregory wrote an article entitled "Make Your Code Faster with noexcept" (2016) that provides more insight. Quote:
First, the compiler doesn't have to do a certain amount of setup -- essentially the infrastructure that enables stack unwinding, and teardown on the way into and out of your function -- if no exceptions will be propagating up from it. ...
Second, the Standard Library is noexcept-aware and uses it to decide between copies, which are generally slow, and moves, which can be orders of magnitude faster, when doing common operations like making a vector bigger.
While this provides how noexcept can help performance, it neglects to provide something important: a benchmark.
Why "Don't Use noexcept"?
I didn't understand this either. I couldn't find many (simple) resources advocating for this camp. I found a paper (from 2011) entitled "noexcept Prevents Library Validation". I'm not sure how relevant it is 13+ years later. Else, Mr. Doumler sent me a good case via email:
Meanwhile, sprinkling
noexcepteverywhere causes lots of other problems, for example if you want to use things like a throwing assert for testing your code that just doesn't work.
Assertions are great for development and debugging; everyone loves them. They are absolutely vital to building any major C/C++ project. This is something I do not want taken away.
Personally, I like the noexcept keyword. It's very useful for documentation and telling others how to use code. We've all been burned by an unexpected exception at some point. It's nice to have in the language in my opinion for this reason.
How This Test Works
It's the exact same as the last time for what I did with final. But for those of you who aren't familiar, let me explain:
- It's a simple A/B test of the
noexceptkeyword being turned on and off with the same codebase - The test is an implementation of Peter Shirley's Ray Tracing in One Weekend book series
- It's fully CPU bound and vanilla-as-possible-modern-standard-C++
- All scenes from the book are rendered 50 times without
noexceptturned on- Each test case has slightly different parameters (e.g. image size, number of cores, random seed, etc.)
- One pass can take about 10-20 hours.
- Only the time spent rendering is measured (using nanoseconds)
- Once again, we repeat the above, but with
noexceptturned on - The off vs. on time difference is calculated as a percentage
- E.g.
off=100 msandon=90 ms. Speedup is 10 ms, so we say that's an +11% performance boost
- E.g.
- All of the above is repeated for a matrix of different chips (AMD, Intel, Apple), different operating systems (Linux, Mac, Windows) and different compilers (GCC, clang, MSVC). This time I tested 10 different configurations
All of the code was built using CMake and compiled with Release mode on, which should give the most performant runtimes (.e.g GCC/clang use -O3 and MSVC has its equivalent).
One important thing I do need to state about this test:
Unfortunately, 100% of all images rendered did not come out the same. The overwhelming super majority did; and when they were different it's negligible. When I first worked on this project I didn't know std::uniform_int_distribution doesn't actually produce the same results on different compilers. (A major issue IMO because that means the standard isn't really portable). A few scenes (such as Book 2's final scene) use an RNG to place objects and generate some noise textures. For example, GCC & MSVC (regardless of CPU/OS) seem to produce the exact same scene and same pixels. But clang has a few objects in different positions and some noise is different. Surprisingly, it is mostly intact compared to the other two. I find this astonishing. But I don't think the difference is that much to require a redo of the experiment. You can see the comparisons in this hefty .zip file.
This discrepancy shouldn't matter that much for two reasons:
- The differences are not too significant (see the .zip linked above if you're skeptical)
- The comparison is
<CHIP> + <OS> + <COMPILER> with <FEATURE> offvs.<CHIP> + <OS> + <COMPILER> with <FEATURE> on
With this said, at the end I do some fun number crunching in a Jupyter notebook and show you some colourful tables & charts alongside analysis.
Please keep in mind that this is a fairly specific benchmark. The (initial) goal of PSRT was to render pretty CGI pictures really fast (without breaking the original books' architecture). It works in a mostly recursive manner. Different applications such as financial analysis, protein folding simulations, or training AIs could have different results.
If you're wondering how I can turn off and on the use of noexcept, it works by (ab)using preprocessor macros:
And thus we powder it all around the code like so:
Once again, this is something I would never EVER do in production code; and you shouldn't either.
Also, I am (now) aware there is noexcept(true) and noexcept(false) that I could have done instead. I didn't know about it at the time and did this ugly C macro. Please forgive me merciless internet commentators.
Almost every function in this project has been marked with this macro. There are a few... exceptions... but these are in the setup or teardown sections of the program. None are in any of the rendering code (which is what is measured). This should allow us to see if marking functions as noexcept help performance or not.
PSRayTracing is not a "real world" application. Primarily serving as an amateur academic project, it does try to be modeled based on real world experiences. Personally, I do believe that commercial products like Unreal Engine or Pixar's RenderMan can serve as better benchmarking tools in general. But I have no idea about their ability to A/B test the C++ language, algorithms, data structures, etc. This is something PSRT has been set up to do.
Results From The Suite
Running the entire test suite an exhausting 22 times, it took cumulatively an absolutely melting 370 hours 🫠🫠
One thing I need to note is the AMD+Windows runs are "artificial" in a sense. When I did the initial analysis I noticed some of the variance in the data was higher than desired. So I ran the suite a second time (once for GCC and MSVC), but for each test case I took the fastest runtime between both attempts. This way AMD+Windows could be given the best chance possible.
So, does noexcept help performance? Here's the grand summary:

We can see here that in some configurations, noexcept gave a half to full percent performance increase; which I think unfortunately could be declared fuzz. In the situations where there was a drop, it's around -2% on average. noexcept isn't really doing that much; it's even acutely harmful for performance. Bar charting that data:
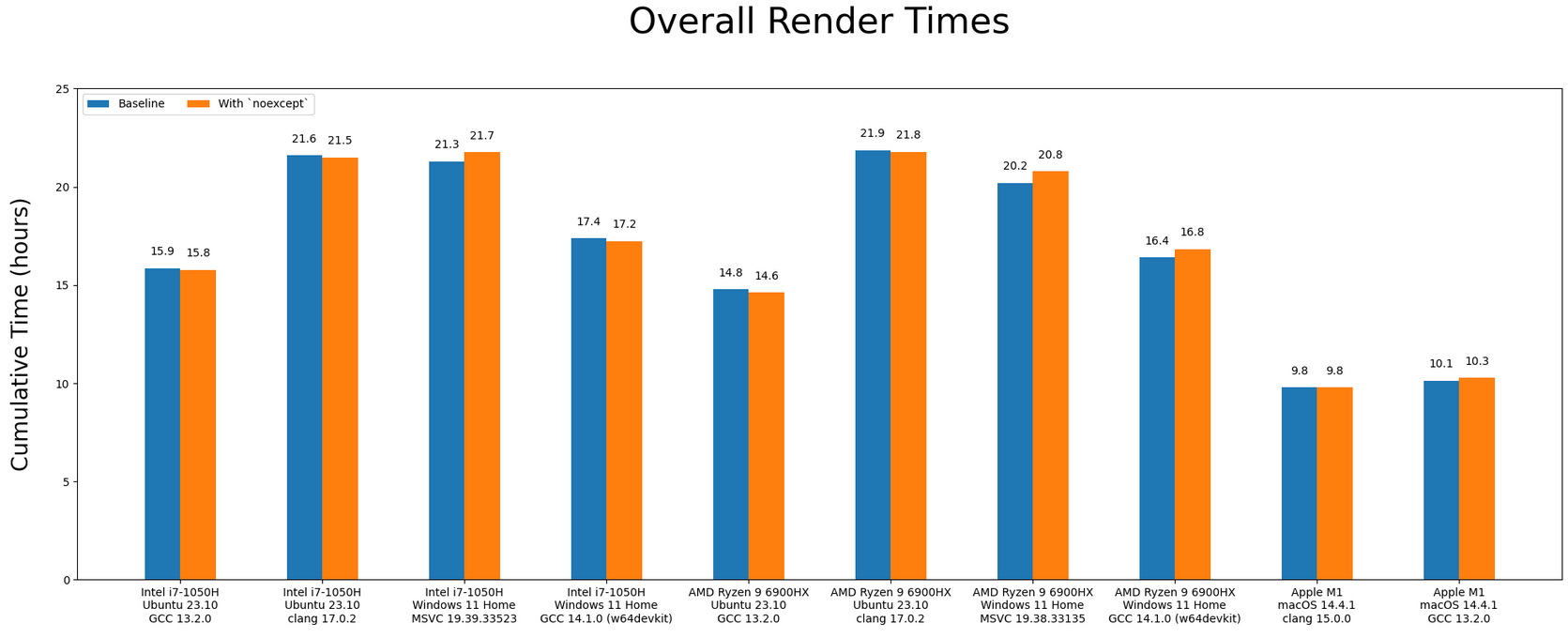
I do need to remind: this is not supposed to be a Monday Night Compiler Smackdown cage match, but once again there are interesting things to observe:
- Like last time, the Apple Silicon trounces everything else, and by a significant amount
- clang (on Linux) is considerably slower than GCC
- If you were to overlay the AMD bars on top of the Intel ones, it almost looks the same
- Your OS (the runtime environment) can have a significant impact on throughput. GCC is doing way better on Linux than Windows.
Summaries are okay, but they don't tell the whole picture. Next, let's see how many of the test cases had a performance increase. While a 1% speedup could not seem like much, for some applications that does equal a lot in cost savings.
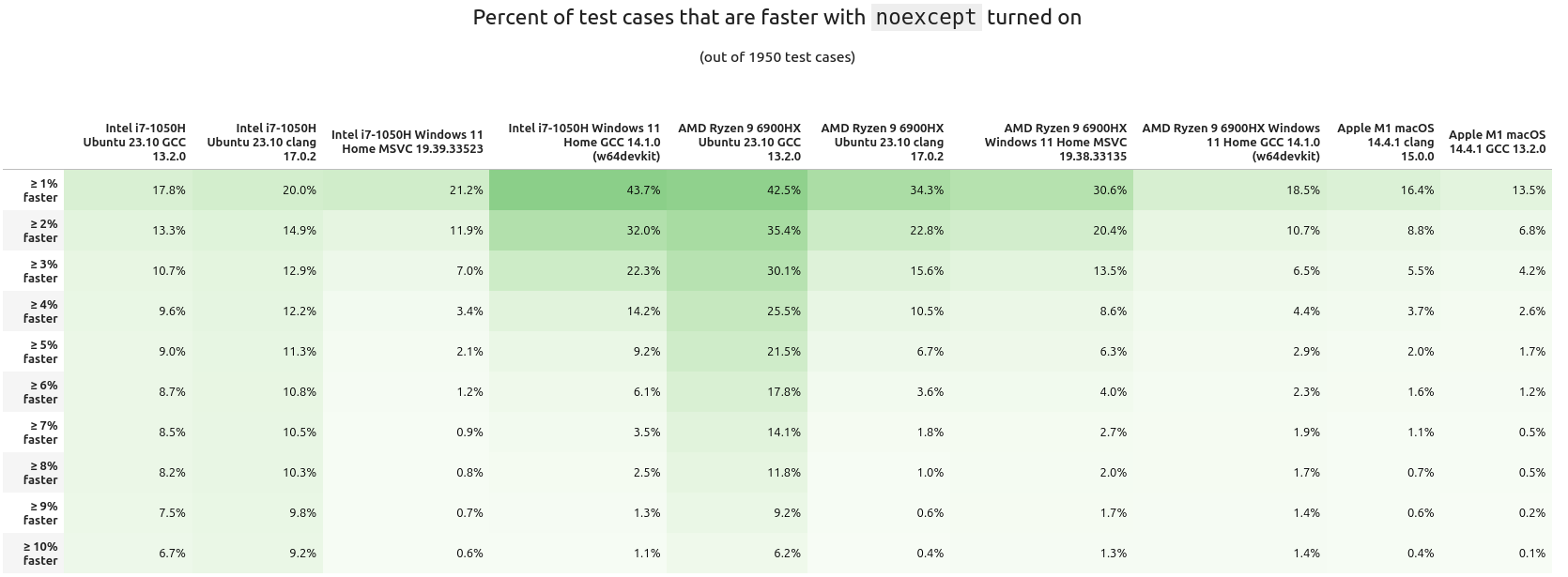
What about the inverse? Here are the percentages of tests having a slowdown with noexcept:
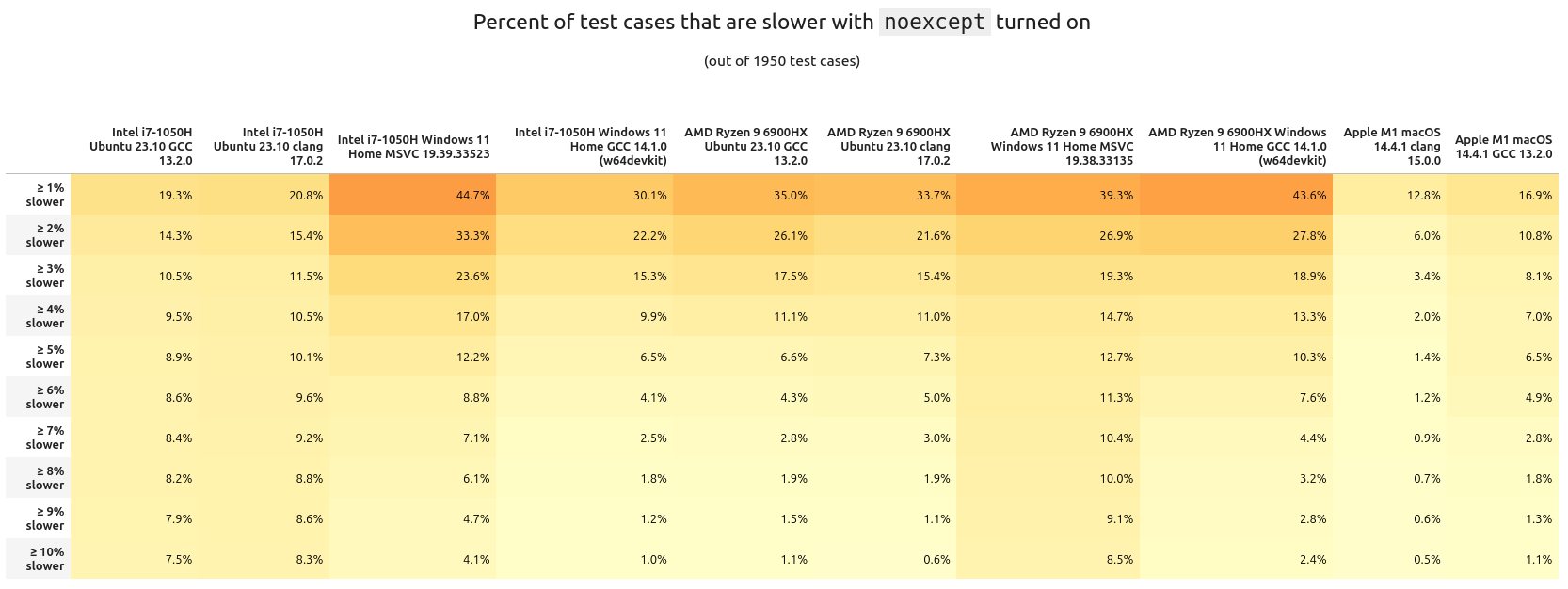
I don't think there's too much we can glean from these tables other than the runtime delta typically stays within the (very) low single percents. Looking at it per scene tells a different story:
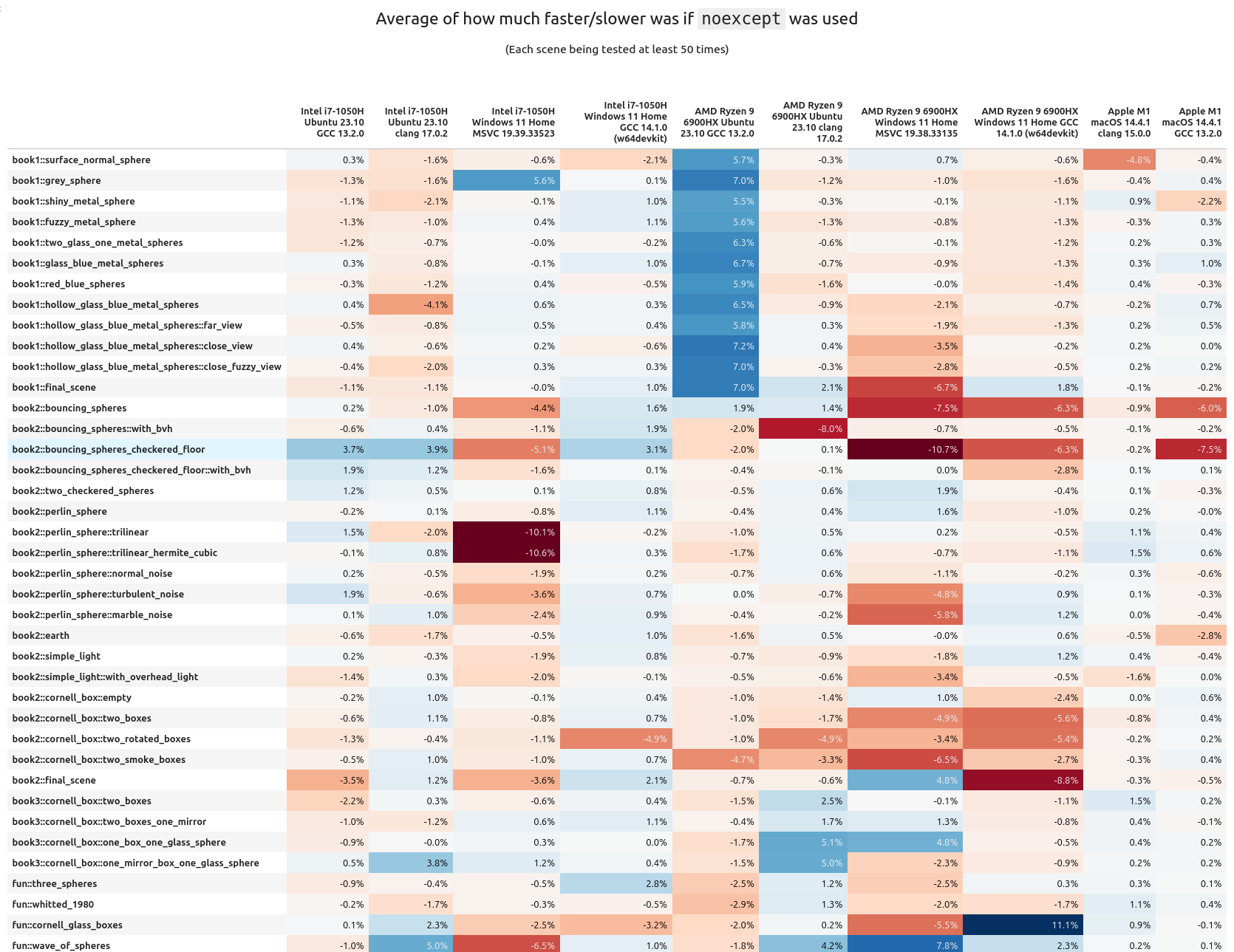
When we look at the average "percentage performance delta per scene", we can clearly see there are some scenes that benefit quite well from noexcept, others are getting hit quite hard. It's also interesting to note how many scenes are barely helped or hurt. Means are good, but seeing the median gives a more fair look at the results. When that is done with the above data, noexcept looks to be less impactful:
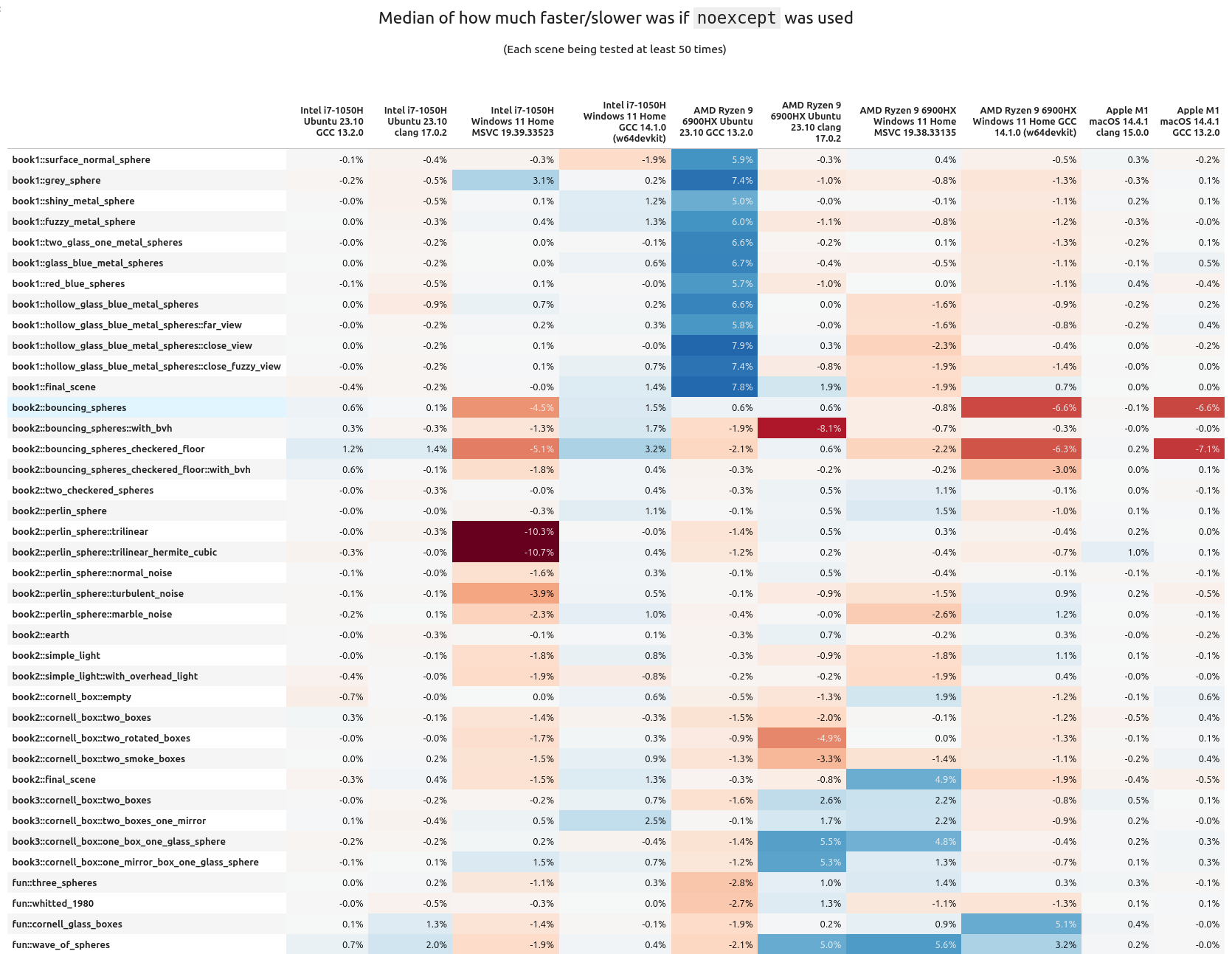
If you want to look at the variance, I have the table right here. I don't think it's as interesting as the above two (though you can have it anyways).
{kind=link}
So overall, it mostly looks like noexcept is either providing a very marginal performance increase or decrease. Personally, I think it is fair to consider the measured performance increase/hit from noexcept to be fuzz; that means it kind of does nothing at all to help runtime speed.
There are some interesting "islands" to take a look at from the above chart.
The AMD+Ubuntu+GCC configuration
We actually see a very significant and consistent performance boost of 6-8% with noexcept turned on! But this is only for the scenes from book 1. When I first saw this I was wondering what could have caused it, and eventually I realized it was related to the architecture of the scene geometry from the first book.
All scene data is stored inside of a std::vector called HittableList. For these scenes, when the ray tracer is traversing through the scene geometry it's doing a sequential search; this was done for simplicity. Any practical graphics engine (realtime or not) will use a tree like structure instead for the scene information.
Starting in book 2 the second task is to use a BVH to store the scene. This provides a massive algorithmic boost to the performance. All subsequent scenes in this book use a BVH instead of a list of objects. This is why we don't see that same speedup in Book 2 (and in fact, a minor performance hit).
From up above, if you remember one of the arguments for "noexcept is faster" is the standard library is aware and can use (faster) memory move operations instead of (slower) copy operations. This is most likely the cause of the performance increase. But the BVH node is not part of std::, and doesn't have move constructors implemented. Therefore when using it noexcept does nearly nothing.
What is more fascinating is that the boost was only seen on AMD+Ubuntu+GCC configuration. Swap out any one of those variables (CPU, OS, or compiler) and no significant gain (in fact a tiny loss) was observed.
Digging A Little Bit Deeper
So... There's actually two BVH tree implementations in PSRT. One of them is the original from book 2. The other one is something I cooked up called BVHNode_MorePerformant. It's 100% API compatible with the standard BVHNode. But under the hood it works a little differently. The quick gist of it: instead of using a tree of pointers to store and traverse, the data is stored in a std::vector in a particular order. The traversal is still done in a tree-like manner, but because of the memory layout of what needs to be checked it can be more efficient. Years ago when I first wrote and tested this class I did see a small speedup in lookups.
It might be good to measure replacing HittableList in book 1 (on AMD+Ubuntu+GCC) with both BVH implementations and see the results:

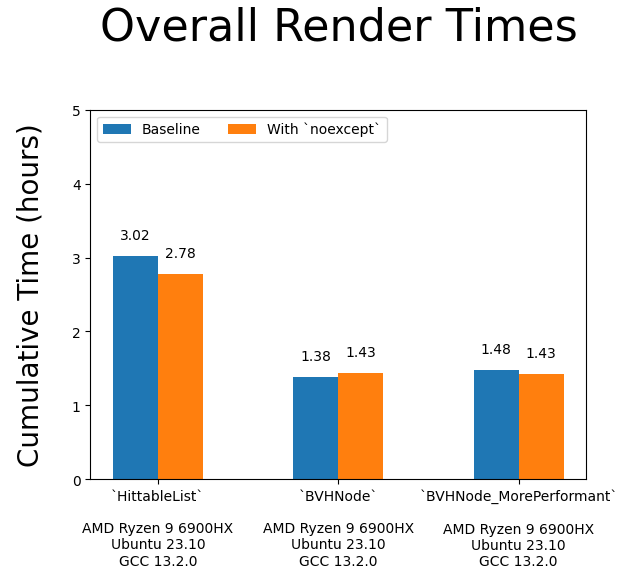
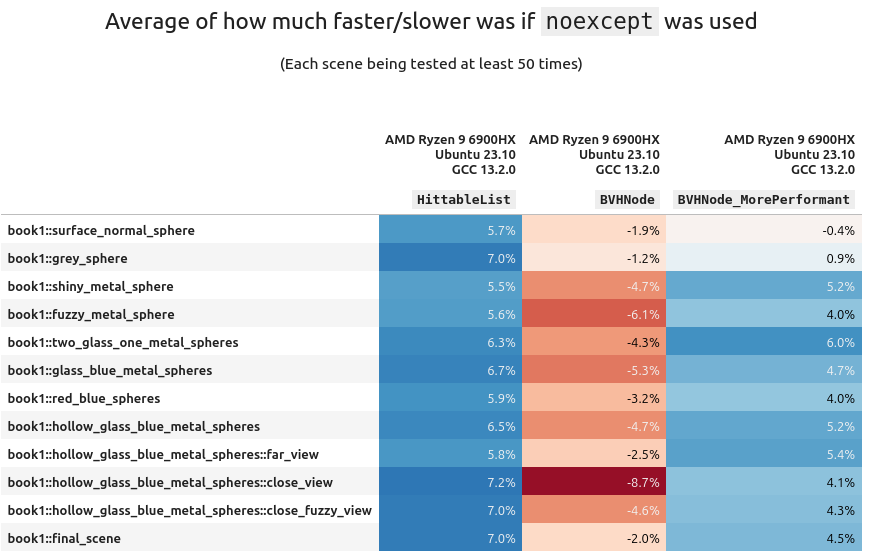
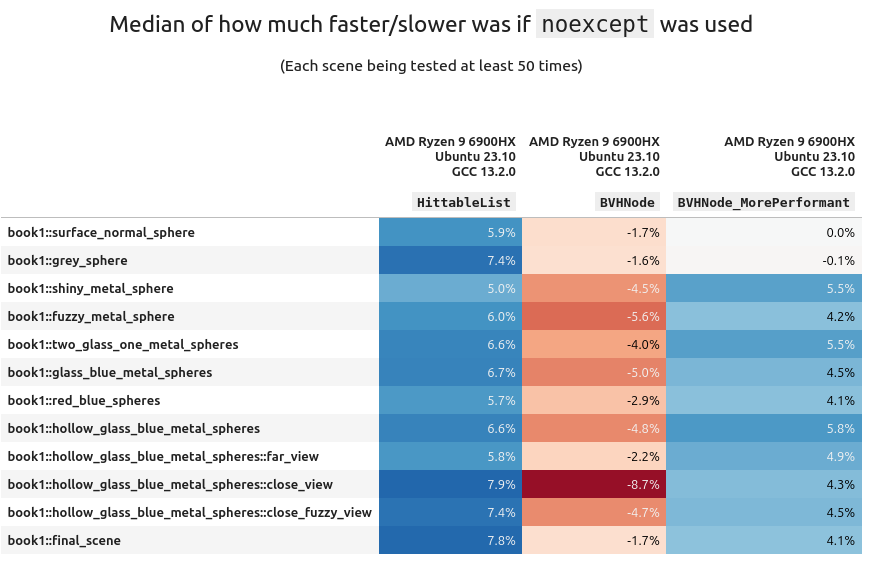
(Variance table available here if you're interested (it's boring)).
{kind=link}
Using std::vector with a dash of noexcept in your code will make that container faster. But we have to remember it's algorithmically inefficient compared to a BVH. And slapping noexcept on top of that (the BVH) can actually be harmful!!. And much to my dismay, my BVHNode_MorePerformant was beaten by the book's default implementation 😭
Shortly below there is a secondary benchmark that has a "reduced" version of HittableList across the configurations. But I would like to address a few other points of interest.
Intel+Windows+MSVC
Looking at the mean/median tables from further above, the Intel+Windows+MSVC run seems to get a little bit of a hit overall when using noexcept. The book2::perlin_sphere:: series of tests steer towards a negative impact. And there are two scenes that have a whopping -10% performance hit with the keyword enabled!!

I am wholly confused as to why this is happening. As you can see, they are pretty simple scenes. Looking at the two cases with the larger performance hit, they are using trilinear interpolation (hermetic and non-hermetic). The code is right here. There are some 3-dimensional loops inside of the interpolation over some std::array objects. This is maybe the source of the slowdown (with noexcept on) but I do not want to speculate too much. It's a very minor subset of the test suite..
If you look at the source code, those three dimensional loops can be manually unrolled, which could (and I stress "could") lead to a performance boost. Sometimes the compiler is smart enough to unroll loops for us in the generated assembly. I didn't want to do it at the time since I thought it was going to make the code overly complex and a maintenance nightmare. This is something to take a look at later.
Looking (a little) More At std::vector
I think it is fair to conclude using std::vector, with noexcept does lead to a performance increase (compared to without the keyword). But this is only happening on one configuration.
I thought it would be best to write up a small testing program (that operates just like HittableList). It does the following:
- Generate a list of random numbers
- Generate a number to search for (could be out of range)
- Try to find that number in the list
- With this part we turn on/off
noexcept
- With this part we turn on/off
The program (of course) was compiled with -O3 and was supplied the same arguments across each configuration. It's run like this and here is the output:
ben@computer:folder$ ./list_test_clang_17 1337 9999999 10000 Checking 9999999 elements, 10000 times... plain average time: 2976 us `noexcept` average time: 2806 us plain median time: 2982 us `noexcept` median time: 2837 us
After testing on each configuration these were the grand results:
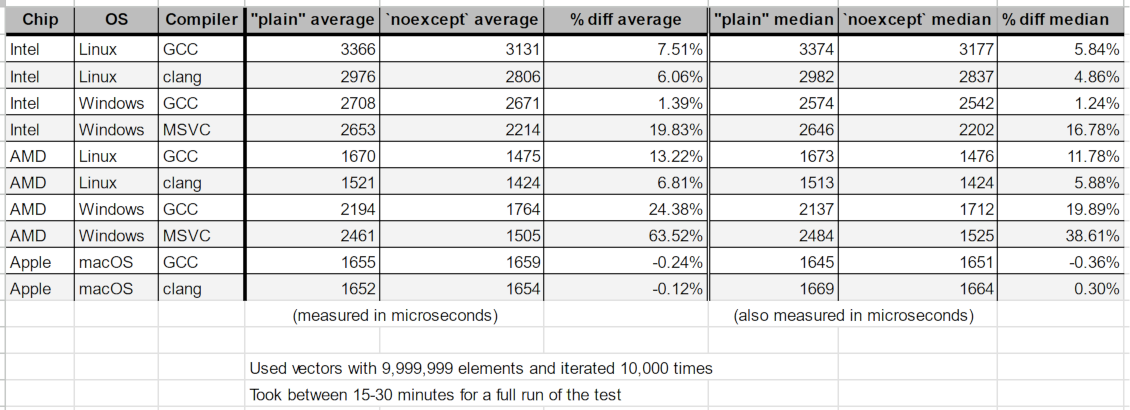
This is a very limited test. We can see there is a fairly consistent speedup for all x86 cases (and a very nice one for AMD+Windows). Apple Silicon has nothing and is likely fuzz.
The people who like noexcept might find this validating, but it's at odds with the tables from measuring PSRT: The speedups here aren't being matched with all the results from book 1, which uses the same "sequential search in std::vector" technique.
Look at the median chart from above. The only reliable speedup came from AMD+Linux+GCC, of around +7%. All other configurations were flat or possibly fuzz. In this mini test AMD+Linux+GCC meters 12% and many other configurations have a significant positive impact from noexcept.
In a more complex program the speedup wasn't reproducible.
From the last article, a commenter on HackerNews mentioned how they didn't like PSRT as a benchmark because it was too large. They preferred tests of small components. This is absolutely ludicrous since as software developers we're not writing small programs. We are building complex systems that interact, move memory around, switch contexts, invalidate cache, wait on resources, etc.
Just because a speedup is seen for a single component doesn't mean it will show up later when programs become large and have a lot of moving parts.
Hopefully I've illustrated this point.
Looking At The Assembly
C++ isn't what's running on the CPU, it's the generated assembly code. Usually to prove that something is faster, I've seen other articles post the generated assembly code, saying "It's optimized!!" I saw this for final, but what is noexcept doing?
Using the above testing program, let's see what the difference is in the generated x86 assembly (from GCC 13 with -O3):
These two look... oddly the same. I'm only spotting one difference, this line where the arguments are swapped in order:
{kind=link}
< cmp DWORD PTR [rdx+rax*4], esi --- > cmp esi, DWORD PTR [rdx+rax*4]
I'm not well versed in assembly, but what I can tell from documentation, it doesn't seem like the order of arguments from the cmp instruction instruction matter. If they do, someone please tell me so I can correct this information. I'd be VERY surprised if this swapped order is what caused the speedup in the limited benchmark above. Anyone who understands assembly much better than I, please provide insight. I would be grateful.
Assembly inspection usually can give insights, but it's no excuse for not measuring your code.
Wrapping up this detour into std::vector, other STL containers might have a performance increase, but we do not know for certain. Thus far only measurements from std::vector have been taken. I have no idea if something like std::unordered_map is impacted by noexcept. There are many other popular alternative container implementations (e.g. Boost, Abseil, Folly, Qt's). Do these get helped, hurt, or placebo'd by noexcept? We don't know.
And keep in mind, in the context of PSRT, we only saw a consistent speedup on one specific configuration (out of ten); some even saw a minute drop. The CPU, OS, and compiler play a role.
I really question whether noexcept helps performance. Just like with final, it doesn't seem to be doing much. Some cases it helps, other cases it hurts. We did find one solid case for Book 1 with AMD+Linux+GCC; but that's it.
And after seeing that overall hit/gain can be from -3% to +1%, I've actually become skeptical and decided to turn it off. I still like the keyword as a documentation tool and hint to other programmers. But for performance, it mostly looks to be a sugar pill.
My most important advice is the same as last time: don't trust anything until you've measured it.
Last Notes
I really didn't think I was going to be running such a similar test again and so quickly. This has inspired me to take a look at a few other performance claims I've heard but yet to have seen numbers posted for.
As for the benchmark itself, I would have loved to throw in some Android and iOS runs as well, but I do not have the bandwidth for that, or infrastructure to make it possible unless I were to quit my day job. We don't have too much high performance computing on mobile and ARM chips yet, but I can see it being something in the future. This is one of the deficiencies of this test. I'd really like to throw Windows+clang into the mix too, but right now there isn't a turnkey solution like how w64devkit provides GCC for Windows. Embedded and other "exotic" chips/runtimes have been given any love either. Maybe even playing with an IBM z16 might be fun 😃
PSRT doesn't also have a good way to "score" how intense a scene is. E.g. number of objects, what kinds, how complex, what materials, textures, lighting, etc. All that can be done right now is "feature on vs. feature off". I'd also want to expand this to other applications out side of computer graphics too.
If you want to follow what goes on with PSRayTracing, check out the GitHub page and subscribe to the releases. But do note the active development is done over on GitLab. You can find all of my measurements and analysis tools in this section of the repo.
EDIT Aug. 10th 2024: There has been discussion about this article on /r/cpp and Hacker News. Read at your leisure.
Till next time~
Vector Pessimization
(This section was added on Aug. 24th, 2024)
I wanted to give it about two weeks before reading the comments in the discussion threads (see above). On Hacker News there was an insightful comment:
... The OP is basically testing the hypothesis "Wrapping a function in `noexcept` will magically make it faster," which is (1) nonsense to anyone who knows how C++ works, and also (2) trivially easy to falsify, because all you have to do is look at the compiled code. Same codegen? Then it's not going to be faster (or slower). You needn't spend all those CPU cycles to find out what you already know by looking.
There has been a fair bit of literature written on the performance of exceptions and noexcept, but OP isn't contributing anything with this particular post.
Here are two of my own blog posts on the subject. The first one is just an explanation of the "vector pessimization" which was also mentioned (obliquely) in OP's post — but with an actual benchmark where you can see why it matters. https://quuxplusone.github.io/blog/2022/08/26/vector-pessimi... https://godbolt.org/z/e4jEcdfT9
The second one is much more interesting, because it shows where `noexcept` can actually have an effect on codegen in the core language. TLDR, it can matter on functions that the compiler can't inline, such as when crossing ABI boundaries or when (as in this case) it's an indirect call through a function pointer. https://quuxplusone.github.io/blog/2022/07/30/type-erased-in...
About 10 days later the author wrote an article entitled noexcept affects libstdc++'s unordered_set. I had some concern that this keyword may impact performance in other STL containers and the author has provided a benchmark which proves such a case. I thank them for that. Vector Pessimization was something I wasn't aware about and does seem like a fairly advanced topic; which isn't apparent at the surface level of C++. I recommend you go and read their posts.
I have never had to do a follow up to any blog post I've ever written; but I feel like I really need to with that last one and clarify a few things.
At the time of publishing I thought I was merely lighting a firecracker, but it seems more like I set off a crate of dynamite. I knew there was going to be some discussion about the results, but I did not anticipate the nearly 350+ comments. People are very particular about performance and benchmarking (as it is fair to be). Everyone is allowed to call BS if they see fit.
It's been three weeks since the article went live. I wanted to take some time for the dust to settle in order to read through what everyone wrote; and respond. If you haven't been privy to any of the discussion, it's been on /r/cpp and Hacker News. Along with some talk on Hackaday.
"I didn't understand how to use final properly"
I saw this comment pop up a few times; that I missed the point of final. The proper use of final wasn't the thesis of my article.
There are plenty of resources explaining how to use it and its purpose in the design of a C++ application. My concern was other articles claiming it can improve performance without a benchmark to back up their statements. Please read the titles of these articles:
- The Performance Benefits of Final Classes (March 2020)
- Using final in C++ to improve performance (November 2022)
- All About C++ final: Boosting Performance with DeVirtualization Techniques (January 2024)
None of these have any metrics posted. But all of these titles imply "final makes code go faster". They all talk about how final is used, including the generated assembly and what's happening at the machine level. That fills the "how?" and "why?" of final. But that isn't a benchmark. To say it improves performance but not have any proof to back it up is dangerous.
For the longest time we have been living in an environment where we skim articles (reading only a headline) and glean information to take it as fact; without actually verifying anything. Part of my previous blog post was trying to highlight what can happen if you do this. It is what I did initially, noticed nothing was matching those claims and decided to test it a bit further.
There was one thing I was wrong about: someone else did a benchmark of final in the past. In their case they found a consistent performance increase. They even re-ran their benchmark and saw the same results from 10 years ago. In my case it was faster in some instances, slower in others. I thank them for reaching out and have updated my older post.
I recall there being a comment about how my "improper" use of final could be a reason why clang had its performance slowdown. My counter to that: GCC had a consistent performance increase with use of the keyword. It was used the keyword as intended (and described by the linked articles above). I put it on many classes that have no further subclassing, and there was a performance boost in this case. Clang on the other hand, had a decrease with the exact same code.
"This isn't a good benchmark"
The previous article was written with the context that others may have read the project's README or have read some of the other prior posts. Let me rewind a little:
PeterShirleyRayTracing, a.k.a. PSRayTracing (a.a.k.a. PSRT) didn't start out as a benchmarking tool. I wanted to revisit a ray tracing book series I read when I was fresh out of university (2016), but this time with all the knowledge of C/C++ I had accumulated since that time. I first went through the books but as an exercise to learn Nim. Between then and 2020 I had seen images from the book pop up online here and there. Mr. Shirley had actually made the mini-books free to read during that time. Reading the book's old code and the newer editions, I noticed there were a lot of areas for improvement in performance. PSRT at first was an experiment in writing performant C++ code, but with some constraints:
- Has to follow the book's original architecture
- Needs to be cleaner and modern
- Must showcase safer C++
- E.g. The book's old code used raw pointers.
std::shared_ptrwas used in later versions; I know this is a bottleneck but that is something I've meant to look at later at later on. (But some other work as been done.)
- E.g. The book's old code used raw pointers.
- Must be standard and portable
- Full support for GCC and Clang (then later MSVC)
- Be "Vanilla C++" as possible. I don't want to force someone to bring in a hefty library
- There is an exception for libraries (like PCG32) that allow an increase in performance and are easily integrated like being a single header library
- Be able to turn on and off changes from the book's original code to see the effects of rewriting parts
- Extending is okay, but they can't violate any of the above rules
- E.g. multithreading was added and some new scenes. The Qt UI is a massive exception to rule no. 6 (but it's not required to run the project)
For the initial revision of PSRT, its code was 4-5x faster than the books' original code (single threaded). I was very proud of this.
Later on a Python script was added so PSRT could be better tested via fuzzing. Parameters could differentiate scenes, how many cores to use, how many samples per pixel, ray depth, etc. It was both meant to check for correctness and measure performance. The measurement of performance only is the time spent rendering. Startup and teardown of PSRT is not measured (and it's negligible). This way if I came across some new technique a change could be made and verify it does not break anything from before. The script has evolved since then.
To explain how the testing and analysis operates a little more simpler:
- Each scene would be fuzz tested, say three times (real tests do way more), and their runtimes recorded. Parameters could be wildly different
- For this example let's say once scene resulted in the times of
[3.1, 10.5, 7.4](real testing used 30 values)
- For this example let's say once scene resulted in the times of
- Then the same suite would be run, but with a change in code
times=[2.7, 8.8, 6.9]
- From this a percentage difference of each test case would be computed
[13%, 17%, 7%]
- A mean & median per scene could be calculated
mean=12.3%,median=13%- Each scene is different. Sometimes radically, other times only slightly. That's why it's important to look at the results per scene
- From there a cumulative "how much faster or slower" for the change could be found
I hope this explains it better.
I neglected to mention what compiler flags were used. All of the code was built with CMake in Release mode. This uses -O3 in most cases. This was something I should have specified first. I know there are other flags that could have been used to eek out some other tiny gains but I do not think it was relevant. I wanted to use the basics and what most people would do by default. I also configured the machines to only run the testing script and PSRT. Nothing else (other than the OS). Networking was disabled as well so nothing could interrupt and consume any resources available.
Simple vs. Complex
One commenter pointed out how they didn't like this, saying that they preferred simpler tests benchmarking atomic units. For example, measuring a bubble sort algorithm and only that. There are already a plethora of tests out there that do just this. That isn't good enough. In the real world we're writing complex systems that interact.
Prefer integration tests; verify the whole product works. Unit testing is good for small components but I only like to do this only when the tiny bits need testing. E.g. if a single function had a bug and we want to double check it going forward.
Other Benchmarks
In all of the comments that I read, I only recall coming across one other benchmark of final; they reported a speedup. But our methods of testing are completely different. They were testing atomic components. Mine was not.
In episode 381 of CppCast it was discussed that there are many practices in the C++ world that are claimed to be more performant without providing any numbers. To anyone who doesn't think this was an adequate benchmark: Do you have an alternative? I'm not finding any. If you don't think this was a good benchmark please explain why and tell me what should be done instead.
"The author provided no analysis about clang's slowdown"
This is one that I think is a more fair criticism of the article. In my defense, this is a topic I do not know that much about. I'm not a compiler engineer, not an expert on the subject of low level performance optimization, nor the inner workings of clang and LLVM. For earlier development of PSRT, tools like perf, flame graphs, valgrind/cachegrind, Godbolt's Compiler Explorer, etc. were used. But I do not feel comfortable providing a deep analysis on the issue with clang.
Time could have been spent researching the subject more and doing proper analysis, but this would have taken months. I did reach out to a friend of mine who works at Apple who provided me with some tips. Reading the comments on Hacker News, avenues seem to be looking at LTO, icache, inlining, etc. (Tickets have already been filed for further investigation.)
Someone did ask me to check the sizes of the generated binaires with final turned on and off. Devirtualization causing excessive inlining could be the cause. With final turned on, the binary was 8192 bytes larger; I'm not sure how significant that is to impact performance. For comparison, GCC's compiled with final was only 4096 bytes larger than no final. But GCC's binary was about 0.2 MB larger (overall) than clang's. I do not think binary size is a factor.
LLVM Engineer
On Hacker News there was a comment left by someone who works on the LLVM project. Quoting them:
"As an LLVM developer, I really wish the author filed a bug report and waited for some analysis BEFORE publishing an article (that may never get amended) that recommends not using this keyword with clang for performance reasons. I suspect there's just a bug in clang."
- I am not sure if this was a bug. I have had performance drops with clang compared to GCC, so I didn't view this as bug worthy. I checked the LLVM issue tracker in the week after publishing and saw that no one else had. So I went ahead and filed a ticket.
- I have amended articles in the past in light of new information. A previous revision of this project added in the aforementioned Qt GUI. When I noticed some bugs in Qt, an engineer from the company reached out to me and I updated the original article. Last week, I thought there were no other benchmarks about
finalin existence. I found out I was wrong and my previous article has been adjusted to include that new information.
If there is a bug in clang/LLVM, it becomes fixed, and the slowdown from usingfinalis reduced (or reversed), I will update the article.
Random Number Generator Might Be The Cause of Clang's Slowdown
The RNG was already a vector for performance improvement in the past. Compared with the original book's code, using PCG's RNG showed improved performance over what was available in standard C++. In the past I was wondering if there could be further improvements in this area.
One reader decided to dig a bit deeper. That person is Ivan Zechev. He's done some amazing work already and found that the issue with clang might have been related to the RNG and std::uniform_real_distribution. Calls to logl were not being properly inlined. And this looks like a long standing issue in clang/LLVM that has never been fixed.
Mr. Zechev sent me a merge request for review, but I have held off on merging it because it actually changed how scenes were set up. This can drastically alter how long it takes to render an image, because the scene is now different. In our case, it was book2::final_scene. At first the floor was completely changed. Later he was able to correct for that, but other elements were not matching. The uniform distributor (in clang) was producing different numbers with his changes. For this, I cannot merge. I commend him for his investigation and will be looking at it in the future. Thank you.
But this only uncovers a horrible problem: Things in std:: are not portable; which kind of means that the "standard library" really isn't ... well... standard. In regards to std::uniform_real_distribution there is some more information here. The C++ standard allows this but it doesn't seem right.
"There's no inspection of the assembly"
The other articles have talked about what assembly is generated. I do not see why it was needed for mine. What the other articles neglected to do was measure. This is the gap I wanted to fill in.
I use C++ at the surface level. I'm pretty sure most people do as well. Part of the point of having a higher level language is to abstract away these lower level concepts. PSRT is meant to be written this way; portable, memory safe, modern C++. Knowing assembly definitely helps, but it should not be a requirement. This is a C++ project.
Update May 15th, 2024:
After posting this article on /r/cpp, user /u/lgovedic provided a well thought out comment. I'd like to repost that here for other readers:
Glad you addressed the comments on both platforms! But I agree with others here that some things were left unaddressed.
When it comes to software performance, I live by the words "don't trust performance numbers you can't explain". Your measurements seem robust, but I think you went too far in assuming that the correlation between the final keyword and overall performance implies a causal relationship.
I respect that you and many others don't want to jump into assembly, and I agree you should be able to just write high-level code. But I do think diving into assembly and providing evidence for the causal link is required if you want to make fundamental statements about C++ performance like "using the final keyword does not always yield performance gains".
To be fair, on a high-level, that statement is not false. And I appreciate that you shed light on the issue so that people will be more mindful of it and measure the performance of their code more often (that's always a good thing).
But from your results and without further investigation, I think a more appropriate statement would be "using the final keyword can drastically alter the layout and size of generated code, which might result in an overall slowdown". Because (again, without further investigation) that's a much more likely explanation, in my opinion. And more importantly, it provides much better advice for using the final keyword than just "be careful"
There will be follow ups and other investigations; but not immediately. I am willing to amend anything in light of new data. This is not my full time job and only a hobby project. Anyone is allowed to contribute and is welcome to do so.
If you're writing C++, there's a good reason (maybe...) as to why you are. And probably, that reason is performance. So often when reading about the language you'll find all sorts of "performance tips and tricks" or "do this instead because it's more efficient". Sometimes you get a good explanation as to why you should. But more often than not, you won't find any hard numbers to back up that claim.
I recently found a peculiar one, the final keyword. I'm a little ashamed I haven't learned about this one earlier. Multiple blog posts claim that it can improve performance(sorry for linking a Medium article). It almost seems like it's almost free, and for a very measly change. After reading you'll notice something interesting: no one posted any metrics. Zero. Nada. Zilch. It essentially is "just trust me bro." Claims of performance improvements aren't worth salt unless you have the numbers to back it up. You also need to be able to reproduce the results. I've been guilty of this in the past (see a PR for Godot I made).
Being a good little engineer with a high performance C++ pet project, I really wanted to validate this claim.
Update May 3rd, 2024: When posting on /r/cpp, someone else did mention they did some perf testing of final before and had some numbers. Theirs was from about a decade ago. I did not find this in my initial searches. The comment thread and their article can be found here.
I keep on finding myself unable to get away from my pandemic era distraction, PSRayTracing. But I think this is actually a VERY good candidate for testing final. It has many derived classes (implementing interfaces) and they are called millions of times in normal execution.
For the (many) of you who haven't been following this project, the quick and skinny on PSRayTracing: it's a ray tracer implemented in C++, derived from Peter Shirley's ray tracing minibooks. It serves mainly an academic purpose, but is modeled after my professional experiences writing C++. The goal is to show readers how you can (re)write C++ to be more performant, clean, and well structured. It has additions and improvements from Dr. Shirley's original code. One of the big features I have in it is the ability to toggle on and off changes from the book (via CMake), as well as being able to supply other options like random seeds, multi-core rendering. It is somewhere 4-5x faster than the original book code (single threaded).
How This Was Done
Leveraging the build system, I added an extra option to the CMakeLists.txt:
Then in C++ we can use (ab)use the pre processor to make a FINAL macro:
And easily it can slapped onto any classes of interest:
Now, we can turn on & off the usage of final in our code base. Yes, it is very hacky and I am disgusted by this myself. I would never do this in an actual product, but it provides us a really nice way to apply the final keyword to the code and turn it on and off as we need it for the experiment.
final was placed on just about every interface. In the architecture we have things such as IHittable, IMaterial, ITexture, etc. Take a look at the final scene from book two, we've got quite a few 10K+ virtual objects in this scenario:

And alternatively, there are some scenes that don't have many (maybe 10):

Initial Concerns:
For PSRT, when testing something that can boost the performance, I first reach for the default scene book2::final. After applying final enabled the console reported:
$ ./PSRayTracing -n 100 -j 2 Scene: book2::final_scene ... Render took 58.587 seconds
But then reverting the change:
$ ./PSRayTracing -n 100 -j 2 Scene: book2::final_scene ... Render took 57.53 seconds
I was a tad bit perplexed? Final was slower?! After a few more runs, I saw a very minimal performance hit. Those blog posts must have lied to me...
Before just tossing this away, I thought it would be best to pull out the verification test script. In a previous revision this was made to essentially fuzz test PSRayTracing (see previous post here). The repo already contains a small set of well known test cases. That suite initially ran for about 20 minutes. But this is where it got a little interesting. The script reported using final slightly faster; wtih final it took 11m 29s. Without final it was 11m 44s. That's +2%. Actually significant.
Something seemed up; more investigation was required.
Big Beefy Testing
Unsatisfied with the above, I created a "large test suite" to be more intensive. On my dev machine it needed to run for 8 hours. This was done by bumping up some of the test parameters. Here are the details on what's been tweaked:
- Number of Times to Test a Scene:
10→30 - Image Size:
[320x240, 400x400, 852x480]→[720x1280, 720x720, 1280x720] - Ray Depth:
[10, 25, 50]→[20, 35, 50] - Samples Per Pixel:
[5, 10, 25]→[25, 50, 75]
Some test cases now would render in 10 seconds, others would take up to 10 minutes to complete. I thought this was much more comprehensive. The smaller suite did around 350+ test cases in 20+ minutes. This now would do 1150+ over the course of 8+ hours.
The performance of a C++ program is also very compiler (and system) dependent as well. So to be more thorough, this was tested across three machines, three operating systems, and with three different compilers; once with final, and once without it enabled. After doing the math, the machines were chugging along for a cumulative 125+ hours. 🫠
Please look at the tables below for specifics, but the configurations were:
- AMD Ryzen 9:
- Linux: GCC & Clang
- Windows: GCC & MSVC
- Apple M1 Mac: GCC & Clang
- Intel i7: Linux GCC
For example, one configuration is "AMD Ryzen 9 with Ubuntu Linux using GCC" and another would be "Apple M1 Mac with macOS using Clang". Not all versions of the compilers were all the same; some were harder to get than others. And I do need to note at the time of writing this (and after gathering the data) a new version of Clang was released. Here, is the general summary of the test results:

This gives off some interesting findings, but tells us one thing right now: across the board, final isn't always faster; it's in fact slower in some situations. Sometimes there is a nice speedup (>1%), other times it is detrimental.
While it may be fun to compare compiler vs. compiler for this application (e.g. "Monday Night Compiler Smackdown"), I do not believe it is a fair thing to do with this data; it's only fair to compare "with final" and "without final" To compare compilers (and on different systems) a more comprehensive testing system is required. But there are some interesting observations:
- Clang on x86_64 is slow.
- Windows is less performant; Microsoft's own compiler is even lagging.
- Apple's silicon chips are absolute powerhouses.
But each scene is different, and contains a different amount of objects that are marked with final. It would be interesting to see percentage wise, how many test cases ran faster or slower with final. Tabling that data, we get this:

That 1% perf boost for some C++ applications is very desirable (e.g. HFT). And if we're hitting it for 50%+ of our test cases it seems like using final is something that we should consider. But on the flip side, we also need to see how the inverse looks. How much slower was it? And for how many test cases?

Clang on x86_64 Linux right there is an absolute "yikes". More than 90% of test cases ran at least 5% slower with final turned on!! Remember how I said a 1% increase is good for some applications? A 1% hit is also bad. Windows with MSVC isn't faring too well either.
As stated way above, this is very scene dependent. Some have only a handful of virtual objects. Others have warehouses full of them. Taking a look (on average) how much faster/slower a scene is with final turned on:

I don't know Pandas that well. I was having some issues creating a Multi-Index table (from arrays) and having the table be both styled and formatted nicely. So instead each column has a configuration number appended to the end of its name. Here is what each number means:
- 0 - GCC 13.2.0 AMD Ryzen 9 6900HX Ubuntu 23.10
- 1 - Clang 17.0.2 AMD Ryzen 9 6900HX Ubuntu 23.10
- 2 - MSVC 17 AMD Ryzen 9 6900HX Windows 11 Home (22631.3085)
- 3 - GCC 13.2.0 (w64devkit) AMD Ryzen 9 6900HX Windows 11 Home (22631.3085)
- 4 - Clang 15 M1 macOS 14.3 (23D56)
- 5 - GCC 13.2.0 (homebrew) M1 macOS 14.3 (23D56)
- 6 - GCC 12.3.0 i7-10750H Ubuntu 22.04.3
So this is where things are really eye popping. On some configurations and specific scenes might have a 10% perf boost. For example book1::final_scene with GCC on AMD & Linux. But other scenes (on the same configuration) have a minimal 0.5% increase such as fun::three_spheres.
But just switching the compiler over to Clang (still running on that AMD & Linux) there's a major perf hit of -5% and -17% (respectively) on those same two scenes!! MSVC (on AMD) looks to be a bit of a mixed bag where some scenes are more performant with final and others ones take a significant hit.
Apple's M1 is somewhat interesting where the gains and hits are very minimal, but GCC has a significant benefit for two scenes.
Whether there were many (or few) virtual objects had next to no correlation if final was a performance boon or hit.
Clang Concerns Me
PSRayTracing also runs on Android and iOS. Most likely a small fraction of apps available for these platforms are written in C++, but there are some programs that make use of language for performance reasons on the two systems. Clang is the compiler that is used for these two platforms.
I unfortunately don't have a framework in place to test performance on Android and iOS like I do with desktop systems But I can do a simple "render-scene-with-same-parameters-one-with-final-and-one-without" test as the app reports how long the process took.
Going from the data above, my hypothesis was that both platforms would be less performant with final turned on. By how much, I don't know. Here are the results:
- iPhone 12: I saw no difference; With and without
finalit took about 2 minutes and 36 seconds to perform the same render. - Pixel 6 Pro:
finalwas slower. It was 49 vs 46 seconds. A difference of three seconds might not seem like much, but that is a 6% slowdown; that is fairly significant. (clang 14 was used here BTW).
If you think I'm being a little silly with these tiny percentages, please take a look at Nicholas Ormrod's 2016 CppCon talks about optimizing std::string for Facebook. I've referenced it before and will continue to do it.
I have no idea if this is a Clang issue or an LLVM one. If it is the latter, this may have implications for other LLVM languages such as Rust and Swift.
For The Future (And What I Wish I Did Instead):
All in all this was a very fascinating detour; but I think I'm satisfied with what's been discovered. If I could redo some things (or be given money to work on this project):
- Have each scene be able to report some metadata. E.g. number of objects, materials, etc. It is easily doable but didn't seem worth it for this study of
final. - Have better knowledge of Jupyter+Pandas. I'm a C++ dev, not a data scientist. I'd like to be able to understand how to better transform the measured results and make it look prettier.
- A way to run the automated tests on Android and iOS. These two platforms can't easily be tested right now and I feel like this is a notable blindspot
run_verfication_tests.pyis turning more into an application (as opposed to a small script).- Features are being bolted on. Better architecture is needed soon.
- Saving and loading testing state was added, but this should have been something from the start and feels like more of a hack to me
- I wish the output of the results were in a JSON format first instead of CSV. I had to fuddle with PyExcel more than desired.
- PNGs are starting to get kinda chunky. One time I ran out of disk space. Lossless WebP might be better as a render output.
- Comparing more Intel chips, and with more compilers. The i7 was something I had lying around.
Conclusions
In case you skimmed to the end, here's the summary:
- Benefit seems to be available for GCC.
- Doesn't affect Apple's chips much at all.
- Do not use
finalwith Clang, and maybe MSVC as well. - It all depends on your configuration/platform; test & measure to see if it's worth it.
Personally, I'm not turning it on. And would in fact, avoid using it. It doesn't seem consistent.
For those who want to look at the raw data and the Jupyter notebook I used to process & present these findings, it's over here.
If you want to take a look at the project, it's up on GitHub (but the active development is done over on GitLab). Looking forward to the next time in one year when I pick up this project again. 😉
Update May 3rd, 2024: This article has generated quite a bit more buzz than I anticipated. I will be doing a follow up soon enough. I think there is a lot of insightful discussion on /r/cpp and Hacker News about this. Please take a look.