I have never had to do a follow up to any blog post I've ever written; but I feel like I really need to with that last one and clarify a few things.
At the time of publishing I thought I was merely lighting a firecracker, but it seems more like I set off a crate of dynamite. I knew there was going to be some discussion about the results, but I did not anticipate the nearly 350+ comments. People are very particular about performance and benchmarking (as it is fair to be). Everyone is allowed to call BS if they see fit.
It's been three weeks since the article went live. I wanted to take some time for the dust to settle in order to read through what everyone wrote; and respond. If you haven't been privy to any of the discussion, it's been on /r/cpp and Hacker News. Along with some talk on Hackaday.
"I didn't understand how to use final properly"
I saw this comment pop up a few times; that I missed the point of final. The proper use of final wasn't the thesis of my article.
There are plenty of resources explaining how to use it and its purpose in the design of a C++ application. My concern was other articles claiming it can improve performance without a benchmark to back up their statements. Please read the titles of these articles:
- The Performance Benefits of Final Classes (March 2020)
- Using final in C++ to improve performance (November 2022)
- All About C++ final: Boosting Performance with DeVirtualization Techniques (January 2024)
None of these have any metrics posted. But all of these titles imply "final makes code go faster". They all talk about how final is used, including the generated assembly and what's happening at the machine level. That fills the "how?" and "why?" of final. But that isn't a benchmark. To say it improves performance but not have any proof to back it up is dangerous.
For the longest time we have been living in an environment where we skim articles (reading only a headline) and glean information to take it as fact; without actually verifying anything. Part of my previous blog post was trying to highlight what can happen if you do this. It is what I did initially, noticed nothing was matching those claims and decided to test it a bit further.
There was one thing I was wrong about: someone else did a benchmark of final in the past. In their case they found a consistent performance increase. They even re-ran their benchmark and saw the same results from 10 years ago. In my case it was faster in some instances, slower in others. I thank them for reaching out and have updated my older post.
I recall there being a comment about how my "improper" use of final could be a reason why clang had its performance slowdown. My counter to that: GCC had a consistent performance increase with use of the keyword. It was used the keyword as intended (and described by the linked articles above). I put it on many classes that have no further subclassing, and there was a performance boost in this case. Clang on the other hand, had a decrease with the exact same code.
"This isn't a good benchmark"
The previous article was written with the context that others may have read the project's README or have read some of the other prior posts. Let me rewind a little:
PeterShirleyRayTracing, a.k.a. PSRayTracing (a.a.k.a. PSRT) didn't start out as a benchmarking tool. I wanted to revisit a ray tracing book series I read when I was fresh out of university (2016), but this time with all the knowledge of C/C++ I had accumulated since that time. I first went through the books but as an exercise to learn Nim. Between then and 2020 I had seen images from the book pop up online here and there. Mr. Shirley had actually made the mini-books free to read during that time. Reading the book's old code and the newer editions, I noticed there were a lot of areas for improvement in performance. PSRT at first was an experiment in writing performant C++ code, but with some constraints:
- Has to follow the book's original architecture
- Needs to be cleaner and modern
- Must showcase safer C++
- E.g. The book's old code used raw pointers.
std::shared_ptrwas used in later versions; I know this is a bottleneck but that is something I've meant to look at later at later on. (But some other work as been done.)
- E.g. The book's old code used raw pointers.
- Must be standard and portable
- Full support for GCC and Clang (then later MSVC)
- Be "Vanilla C++" as possible. I don't want to force someone to bring in a hefty library
- There is an exception for libraries (like PCG32) that allow an increase in performance and are easily integrated like being a single header library
- Be able to turn on and off changes from the book's original code to see the effects of rewriting parts
- Extending is okay, but they can't violate any of the above rules
- E.g. multithreading was added and some new scenes. The Qt UI is a massive exception to rule no. 6 (but it's not required to run the project)
For the initial revision of PSRT, its code was 4-5x faster than the books' original code (single threaded). I was very proud of this.
Later on a Python script was added so PSRT could be better tested via fuzzing. Parameters could differentiate scenes, how many cores to use, how many samples per pixel, ray depth, etc. It was both meant to check for correctness and measure performance. The measurement of performance only is the time spent rendering. Startup and teardown of PSRT is not measured (and it's negligible). This way if I came across some new technique a change could be made and verify it does not break anything from before. The script has evolved since then.
To explain how the testing and analysis operates a little more simpler:
- Each scene would be fuzz tested, say three times (real tests do way more), and their runtimes recorded. Parameters could be wildly different
- For this example let's say once scene resulted in the times of
[3.1, 10.5, 7.4](real testing used 30 values)
- For this example let's say once scene resulted in the times of
- Then the same suite would be run, but with a change in code
times=[2.7, 8.8, 6.9]
- From this a percentage difference of each test case would be computed
[13%, 17%, 7%]
- A mean & median per scene could be calculated
mean=12.3%,median=13%- Each scene is different. Sometimes radically, other times only slightly. That's why it's important to look at the results per scene
- From there a cumulative "how much faster or slower" for the change could be found
I hope this explains it better.
I neglected to mention what compiler flags were used. All of the code was built with CMake in Release mode. This uses -O3 in most cases. This was something I should have specified first. I know there are other flags that could have been used to eek out some other tiny gains but I do not think it was relevant. I wanted to use the basics and what most people would do by default. I also configured the machines to only run the testing script and PSRT. Nothing else (other than the OS). Networking was disabled as well so nothing could interrupt and consume any resources available.
Simple vs. Complex
One commenter pointed out how they didn't like this, saying that they preferred simpler tests benchmarking atomic units. For example, measuring a bubble sort algorithm and only that. There are already a plethora of tests out there that do just this. That isn't good enough. In the real world we're writing complex systems that interact.
Prefer integration tests; verify the whole product works. Unit testing is good for small components but I only like to do this only when the tiny bits need testing. E.g. if a single function had a bug and we want to double check it going forward.
Other Benchmarks
In all of the comments that I read, I only recall coming across one other benchmark of final; they reported a speedup. But our methods of testing are completely different. They were testing atomic components. Mine was not.
In episode 381 of CppCast it was discussed that there are many practices in the C++ world that are claimed to be more performant without providing any numbers. To anyone who doesn't think this was an adequate benchmark: Do you have an alternative? I'm not finding any. If you don't think this was a good benchmark please explain why and tell me what should be done instead.
"The author provided no analysis about clang's slowdown"
This is one that I think is a more fair criticism of the article. In my defense, this is a topic I do not know that much about. I'm not a compiler engineer, not an expert on the subject of low level performance optimization, nor the inner workings of clang and LLVM. For earlier development of PSRT, tools like perf, flame graphs, valgrind/cachegrind, Godbolt's Compiler Explorer, etc. were used. But I do not feel comfortable providing a deep analysis on the issue with clang.
Time could have been spent researching the subject more and doing proper analysis, but this would have taken months. I did reach out to a friend of mine who works at Apple who provided me with some tips. Reading the comments on Hacker News, avenues seem to be looking at LTO, icache, inlining, etc. (Tickets have already been filed for further investigation.)
Someone did ask me to check the sizes of the generated binaires with final turned on and off. Devirtualization causing excessive inlining could be the cause. With final turned on, the binary was 8192 bytes larger; I'm not sure how significant that is to impact performance. For comparison, GCC's compiled with final was only 4096 bytes larger than no final. But GCC's binary was about 0.2 MB larger (overall) than clang's. I do not think binary size is a factor.
LLVM Engineer
On Hacker News there was a comment left by someone who works on the LLVM project. Quoting them:
"As an LLVM developer, I really wish the author filed a bug report and waited for some analysis BEFORE publishing an article (that may never get amended) that recommends not using this keyword with clang for performance reasons. I suspect there's just a bug in clang."
- I am not sure if this was a bug. I have had performance drops with clang compared to GCC, so I didn't view this as bug worthy. I checked the LLVM issue tracker in the week after publishing and saw that no one else had. So I went ahead and filed a ticket.
- I have amended articles in the past in light of new information. A previous revision of this project added in the aforementioned Qt GUI. When I noticed some bugs in Qt, an engineer from the company reached out to me and I updated the original article. Last week, I thought there were no other benchmarks about
finalin existence. I found out I was wrong and my previous article has been adjusted to include that new information.
If there is a bug in clang/LLVM, it becomes fixed, and the slowdown from usingfinalis reduced (or reversed), I will update the article.
Random Number Generator Might Be The Cause of Clang's Slowdown
The RNG was already a vector for performance improvement in the past. Compared with the original book's code, using PCG's RNG showed improved performance over what was available in standard C++. In the past I was wondering if there could be further improvements in this area.
One reader decided to dig a bit deeper. That person is Ivan Zechev. He's done some amazing work already and found that the issue with clang might have been related to the RNG and std::uniform_real_distribution. Calls to logl were not being properly inlined. And this looks like a long standing issue in clang/LLVM that has never been fixed.
Mr. Zechev sent me a merge request for review, but I have held off on merging it because it actually changed how scenes were set up. This can drastically alter how long it takes to render an image, because the scene is now different. In our case, it was book2::final_scene. At first the floor was completely changed. Later he was able to correct for that, but other elements were not matching. The uniform distributor (in clang) was producing different numbers with his changes. For this, I cannot merge. I commend him for his investigation and will be looking at it in the future. Thank you.
But this only uncovers a horrible problem: Things in std:: are not portable; which kind of means that the "standard library" really isn't ... well... standard. In regards to std::uniform_real_distribution there is some more information here. The C++ standard allows this but it doesn't seem right.
"There's no inspection of the assembly"
The other articles have talked about what assembly is generated. I do not see why it was needed for mine. What the other articles neglected to do was measure. This is the gap I wanted to fill in.
I use C++ at the surface level. I'm pretty sure most people do as well. Part of the point of having a higher level language is to abstract away these lower level concepts. PSRT is meant to be written this way; portable, memory safe, modern C++. Knowing assembly definitely helps, but it should not be a requirement. This is a C++ project.
Update May 15th, 2024:
After posting this article on /r/cpp, user /u/lgovedic provided a well thought out comment. I'd like to repost that here for other readers:
Glad you addressed the comments on both platforms! But I agree with others here that some things were left unaddressed.
When it comes to software performance, I live by the words "don't trust performance numbers you can't explain". Your measurements seem robust, but I think you went too far in assuming that the correlation between the final keyword and overall performance implies a causal relationship.
I respect that you and many others don't want to jump into assembly, and I agree you should be able to just write high-level code. But I do think diving into assembly and providing evidence for the causal link is required if you want to make fundamental statements about C++ performance like "using the final keyword does not always yield performance gains".
To be fair, on a high-level, that statement is not false. And I appreciate that you shed light on the issue so that people will be more mindful of it and measure the performance of their code more often (that's always a good thing).
But from your results and without further investigation, I think a more appropriate statement would be "using the final keyword can drastically alter the layout and size of generated code, which might result in an overall slowdown". Because (again, without further investigation) that's a much more likely explanation, in my opinion. And more importantly, it provides much better advice for using the final keyword than just "be careful"
There will be follow ups and other investigations; but not immediately. I am willing to amend anything in light of new data. This is not my full time job and only a hobby project. Anyone is allowed to contribute and is welcome to do so.
If you're writing C++, there's a good reason (maybe...) as to why you are. And probably, that reason is performance. So often when reading about the language you'll find all sorts of "performance tips and tricks" or "do this instead because it's more efficient". Sometimes you get a good explanation as to why you should. But more often than not, you won't find any hard numbers to back up that claim.
I recently found a peculiar one, the final keyword. I'm a little ashamed I haven't learned about this one earlier. Multiple blog posts claim that it can improve performance(sorry for linking a Medium article). It almost seems like it's almost free, and for a very measly change. After reading you'll notice something interesting: no one posted any metrics. Zero. Nada. Zilch. It essentially is "just trust me bro." Claims of performance improvements aren't worth salt unless you have the numbers to back it up. You also need to be able to reproduce the results. I've been guilty of this in the past (see a PR for Godot I made).
Being a good little engineer with a high performance C++ pet project, I really wanted to validate this claim.
Update May 3rd, 2024: When posting on /r/cpp, someone else did mention they did some perf testing of final before and had some numbers. Theirs was from about a decade ago. I did not find this in my initial searches. The comment thread and their article can be found here.
I keep on finding myself unable to get away from my pandemic era distraction, PSRayTracing. But I think this is actually a VERY good candidate for testing final. It has many derived classes (implementing interfaces) and they are called millions of times in normal execution.
For the (many) of you who haven't been following this project, the quick and skinny on PSRayTracing: it's a ray tracer implemented in C++, derived from Peter Shirley's ray tracing minibooks. It serves mainly an academic purpose, but is modeled after my professional experiences writing C++. The goal is to show readers how you can (re)write C++ to be more performant, clean, and well structured. It has additions and improvements from Dr. Shirley's original code. One of the big features I have in it is the ability to toggle on and off changes from the book (via CMake), as well as being able to supply other options like random seeds, multi-core rendering. It is somewhere 4-5x faster than the original book code (single threaded).
How This Was Done
Leveraging the build system, I added an extra option to the CMakeLists.txt:
Then in C++ we can use (ab)use the pre processor to make a FINAL macro:
And easily it can slapped onto any classes of interest:
Now, we can turn on & off the usage of final in our code base. Yes, it is very hacky and I am disgusted by this myself. I would never do this in an actual product, but it provides us a really nice way to apply the final keyword to the code and turn it on and off as we need it for the experiment.
final was placed on just about every interface. In the architecture we have things such as IHittable, IMaterial, ITexture, etc. Take a look at the final scene from book two, we've got quite a few 10K+ virtual objects in this scenario:

And alternatively, there are some scenes that don't have many (maybe 10):

Initial Concerns:
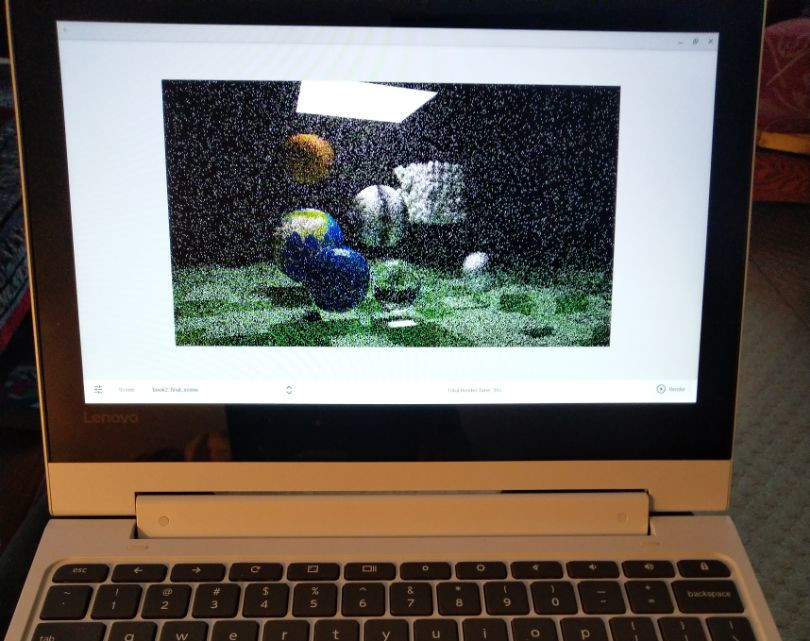
For PSRT, when testing something that can boost the performance, I first reach for the default scene book2::final. After applying final enabled the console reported:
$ ./PSRayTracing -n 100 -j 2 Scene: book2::final_scene ... Render took 58.587 seconds
But then reverting the change:
$ ./PSRayTracing -n 100 -j 2 Scene: book2::final_scene ... Render took 57.53 seconds
I was a tad bit perplexed? Final was slower?! After a few more runs, I saw a very minimal performance hit. Those blog posts must have lied to me...
Before just tossing this away, I thought it would be best to pull out the verification test script. In a previous revision this was made to essentially fuzz test PSRayTracing (see previous post here). The repo already contains a small set of well known test cases. That suite initially ran for about 20 minutes. But this is where it got a little interesting. The script reported using final slightly faster; wtih final it took 11m 29s. Without final it was 11m 44s. That's +2%. Actually significant.
Something seemed up; more investigation was required.
Big Beefy Testing
Unsatisfied with the above, I created a "large test suite" to be more intensive. On my dev machine it needed to run for 8 hours. This was done by bumping up some of the test parameters. Here are the details on what's been tweaked:
- Number of Times to Test a Scene:
10→30 - Image Size:
[320x240, 400x400, 852x480]→[720x1280, 720x720, 1280x720] - Ray Depth:
[10, 25, 50]→[20, 35, 50] - Samples Per Pixel:
[5, 10, 25]→[25, 50, 75]
Some test cases now would render in 10 seconds, others would take up to 10 minutes to complete. I thought this was much more comprehensive. The smaller suite did around 350+ test cases in 20+ minutes. This now would do 1150+ over the course of 8+ hours.
The performance of a C++ program is also very compiler (and system) dependent as well. So to be more thorough, this was tested across three machines, three operating systems, and with three different compilers; once with final, and once without it enabled. After doing the math, the machines were chugging along for a cumulative 125+ hours. 🫠
Please look at the tables below for specifics, but the configurations were:
- AMD Ryzen 9:
- Linux: GCC & Clang
- Windows: GCC & MSVC
- Apple M1 Mac: GCC & Clang
- Intel i7: Linux GCC
For example, one configuration is "AMD Ryzen 9 with Ubuntu Linux using GCC" and another would be "Apple M1 Mac with macOS using Clang". Not all versions of the compilers were all the same; some were harder to get than others. And I do need to note at the time of writing this (and after gathering the data) a new version of Clang was released. Here, is the general summary of the test results:

This gives off some interesting findings, but tells us one thing right now: across the board, final isn't always faster; it's in fact slower in some situations. Sometimes there is a nice speedup (>1%), other times it is detrimental.
While it may be fun to compare compiler vs. compiler for this application (e.g. "Monday Night Compiler Smackdown"), I do not believe it is a fair thing to do with this data; it's only fair to compare "with final" and "without final" To compare compilers (and on different systems) a more comprehensive testing system is required. But there are some interesting observations:
- Clang on x86_64 is slow.
- Windows is less performant; Microsoft's own compiler is even lagging.
- Apple's silicon chips are absolute powerhouses.
But each scene is different, and contains a different amount of objects that are marked with final. It would be interesting to see percentage wise, how many test cases ran faster or slower with final. Tabling that data, we get this:

That 1% perf boost for some C++ applications is very desirable (e.g. HFT). And if we're hitting it for 50%+ of our test cases it seems like using final is something that we should consider. But on the flip side, we also need to see how the inverse looks. How much slower was it? And for how many test cases?

Clang on x86_64 Linux right there is an absolute "yikes". More than 90% of test cases ran at least 5% slower with final turned on!! Remember how I said a 1% increase is good for some applications? A 1% hit is also bad. Windows with MSVC isn't faring too well either.
As stated way above, this is very scene dependent. Some have only a handful of virtual objects. Others have warehouses full of them. Taking a look (on average) how much faster/slower a scene is with final turned on:

I don't know Pandas that well. I was having some issues creating a Multi-Index table (from arrays) and having the table be both styled and formatted nicely. So instead each column has a configuration number appended to the end of its name. Here is what each number means:
- 0 - GCC 13.2.0 AMD Ryzen 9 6900HX Ubuntu 23.10
- 1 - Clang 17.0.2 AMD Ryzen 9 6900HX Ubuntu 23.10
- 2 - MSVC 17 AMD Ryzen 9 6900HX Windows 11 Home (22631.3085)
- 3 - GCC 13.2.0 (w64devkit) AMD Ryzen 9 6900HX Windows 11 Home (22631.3085)
- 4 - Clang 15 M1 macOS 14.3 (23D56)
- 5 - GCC 13.2.0 (homebrew) M1 macOS 14.3 (23D56)
- 6 - GCC 12.3.0 i7-10750H Ubuntu 22.04.3
So this is where things are really eye popping. On some configurations and specific scenes might have a 10% perf boost. For example book1::final_scene with GCC on AMD & Linux. But other scenes (on the same configuration) have a minimal 0.5% increase such as fun::three_spheres.
But just switching the compiler over to Clang (still running on that AMD & Linux) there's a major perf hit of -5% and -17% (respectively) on those same two scenes!! MSVC (on AMD) looks to be a bit of a mixed bag where some scenes are more performant with final and others ones take a significant hit.
Apple's M1 is somewhat interesting where the gains and hits are very minimal, but GCC has a significant benefit for two scenes.
Whether there were many (or few) virtual objects had next to no correlation if final was a performance boon or hit.
Clang Concerns Me
PSRayTracing also runs on Android and iOS. Most likely a small fraction of apps available for these platforms are written in C++, but there are some programs that make use of language for performance reasons on the two systems. Clang is the compiler that is used for these two platforms.
I unfortunately don't have a framework in place to test performance on Android and iOS like I do with desktop systems But I can do a simple "render-scene-with-same-parameters-one-with-final-and-one-without" test as the app reports how long the process took.
Going from the data above, my hypothesis was that both platforms would be less performant with final turned on. By how much, I don't know. Here are the results:
- iPhone 12: I saw no difference; With and without
finalit took about 2 minutes and 36 seconds to perform the same render. - Pixel 6 Pro:
finalwas slower. It was 49 vs 46 seconds. A difference of three seconds might not seem like much, but that is a 6% slowdown; that is fairly significant. (clang 14 was used here BTW).
If you think I'm being a little silly with these tiny percentages, please take a look at Nicholas Ormrod's 2016 CppCon talks about optimizing std::string for Facebook. I've referenced it before and will continue to do it.
I have no idea if this is a Clang issue or an LLVM one. If it is the latter, this may have implications for other LLVM languages such as Rust and Swift.
For The Future (And What I Wish I Did Instead):
All in all this was a very fascinating detour; but I think I'm satisfied with what's been discovered. If I could redo some things (or be given money to work on this project):
- Have each scene be able to report some metadata. E.g. number of objects, materials, etc. It is easily doable but didn't seem worth it for this study of
final. - Have better knowledge of Jupyter+Pandas. I'm a C++ dev, not a data scientist. I'd like to be able to understand how to better transform the measured results and make it look prettier.
- A way to run the automated tests on Android and iOS. These two platforms can't easily be tested right now and I feel like this is a notable blindspot
run_verfication_tests.pyis turning more into an application (as opposed to a small script).- Features are being bolted on. Better architecture is needed soon.
- Saving and loading testing state was added, but this should have been something from the start and feels like more of a hack to me
- I wish the output of the results were in a JSON format first instead of CSV. I had to fuddle with PyExcel more than desired.
- PNGs are starting to get kinda chunky. One time I ran out of disk space. Lossless WebP might be better as a render output.
- Comparing more Intel chips, and with more compilers. The i7 was something I had lying around.
Conclusions
In case you skimmed to the end, here's the summary:
- Benefit seems to be available for GCC.
- Doesn't affect Apple's chips much at all.
- Do not use
finalwith Clang, and maybe MSVC as well. - It all depends on your configuration/platform; test & measure to see if it's worth it.
Personally, I'm not turning it on. And would in fact, avoid using it. It doesn't seem consistent.
For those who want to look at the raw data and the Jupyter notebook I used to process & present these findings, it's over here.
If you want to take a look at the project, it's up on GitHub (but the active development is done over on GitLab). Looking forward to the next time in one year when I pick up this project again. 😉
Update May 3rd, 2024: This article has generated quite a bit more buzz than I anticipated. I will be doing a follow up soon enough. I think there is a lot of insightful discussion on /r/cpp and Hacker News about this. Please take a look.
I still can't seem to escape my PSRayTracing project. If you maybe remember, it was only available on the Google Play Store; despite the code working for iOS. The reason being that I didn't want to pay for the $100/yr subscription Apple required to publish (even) free apps.
Recently I've wanted to get back into app development a bit, so I bit the cost and formally published a version to the Apple App Store. If you'd like to take PSRayTracing out for a spin on your iDevice (or M1/M2 Mac), you can get by clicking the button below.
Software translation is a topic that I don't see being discussed too much. It's something I've wanted to write a blog post about for a while now. At most, all I see is the "wrap your user facing strings in a translation macro", and call it a day. There's a lot more to be concerned about in my opinion.
Despite being in the industry for only a few years, I've gotten to work quite a bit with making software speak more than one language. I've led translation projects in the past. Taking some products from a single language (English) to many; whilst leaving breathing room for more. When it comes to this topic, there is both a technical and non-technical side. In order to be good little developers, I think it is very important to cover the softer parts as well.
This blog post (probably my second longest thus far,) is divided in about three major sections. Feel free to skip a section if it doesn't interest you.
- Localization in Qt apps
- Good guidelines for localization
- A story of localization from a previous job
Professionally, I am a C++/Qt programmer. I may be a bit biased here, but I feel that Qt has one of the best localization infrastructures out there. It's got your basic "replace this [English] string with that [French] translation" feature, yet it also provides GUI translation tools (such as Linguist) and locale specific resource/asset loading. While this guide will have a focus on use of the Qt framework, it will also cover general principles as well.
If you're looking for a non-Qt solution, Boost.Locale looks to be an excellent alternative. Outside of C++ land, there's the lower-level GNU gettext which is available for many other languages (Boost.Locale actually uses this under the hood). I've not used these solutions myself, but they are battle hardened throughout the years and are worth your attention.
If there is one component I wish I could rip out of Qt and shove it into its own independent library it would be the string handling (QString et. al) and localization ecosystem. It has some of the most handy string manipulation functions out there. I wish there was a Qt-like-but-non-Qt equivalent out there that I could pull into other projects of mine.
The one thing I will not talk about is money. That's a whole other can of worms you can go hire an overpriced consultant for.
What prompted me to write this post was extending the PSRayTracing app once more. I wanted to (and did) add both a German and Japanese translation. It's fairly tiny, only has about 30 user facing strings. It's now live on Google Play (EDIT Oct 23rd, 2023: and now Apple App Store too) if you want to take it for a spin. And the full source code is available on GitHub. Please help me, I can't escape this project no matter what I do...
![]()
Translation vs. Localization
This gets into philosophical things here a bit more, but I think it's an important matter to cover. When you are trying to internationalize an app of yours, you should strive for localization over simple translation. If you're wondering what's the difference, here's the quick version:
Translation → The reinterpretation of meaning from one language into another, but keeping things such as names and places intact.
Localization → Translation, but also changing specific elements to better match with the target language/culture.
If you're wondering why localization is better, a good example I can think of is the colour red. In many western cultures, red colours are usually reserved for the "no good bad thing". E.g. stop signs, error messages, etc. But in Chinese culture, red elicits good luck and happiness. This is a very stark contrast in meaning. It could lead to some dangerous behavior if not properly addressed.
Shoot for localization.
Localization in Qt
Qt has their own guides on this subject. I would recommend giving them a brief read as well:
To start things off simple, let's just talk about strings for the moment. In your application, strings can be divided into two groups:
- User facing strings/messages. This is what you want to translate
- Non-user facing strings/messages. These would be your debug messages, (some) file paths, shell calls, etc
Your user facing strings will go into what's known as a .ts file. This is what you would hand to a translator to, well, translate. You can have multiple of these for a project. It should be one .ts file per language. E.g. myapp_en_US.ts, myapp_de_DE.ts, etc.
Translations are put back into the .ts file by the translator via a tool called "Linguist". It has very nice features such as adding notes, marking completeness, phrasebook, and more. Once you've received your .ts file, you must then transform it into a .qm file. These are known as the "Translation Modules". They are what needs to be shipped with your application to support a different language.
User Messages
If you want to collect those user facing strings into something you can hand off to a translator, you'll need to use the QObject::tr() function. If your string lives in QML, then use qsTr(). It works exactly the same (down to the parameters too). Explaining the arguments, we've got:
const char *sourceTextconst char *disambiguation = nullptrint n = -1
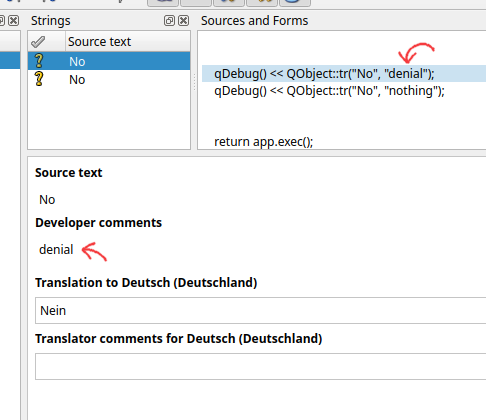
sourceText is the most important one here. This is the text that you want to show to a user. "User Facing Messages" as I tend to call it. Next we have disambiguation. This is important if you have an overloaded word, but when translating to another language you need to use a more specific case. If you're confused about this, let's do an English → German example.
- "No, that is false" → "Nein, das ist falsch"
- "I have no idea" → "I habe keine Ahnung"
Even if you haven't taken a German 101 class, you probably know that "nein" means "no". But that's for the case when you want to disaffirm or deny something. But when you state that you have "no units of something", you need to use "kein". Here's what will show up in Linguist when specify a disambiguation for two matching sourceTexts.
Handy, isn't it?
As for the last argument, we've got an n. This is a "plural specifier". As English speakers, notice how we say things like:
- 0 Apples
- 1 Apple
- 2 Apples
At some point in your life you've seen some software that showed text such as 4 Apple(s). While this is programmer friendly, it isn't really natural. I'm sure you're already thinking of some solution where you can use conditional logic to show different strings; don't do that.
- That gets ugly, and fast
- That little
nparameter? Qt implements this already for you
Pluralization rules can get quite nasty for other languages. There's a very old Qt Quarterly article that goes into this whole plural string thing way better than I can. Go read it. It has everything else I want to say.
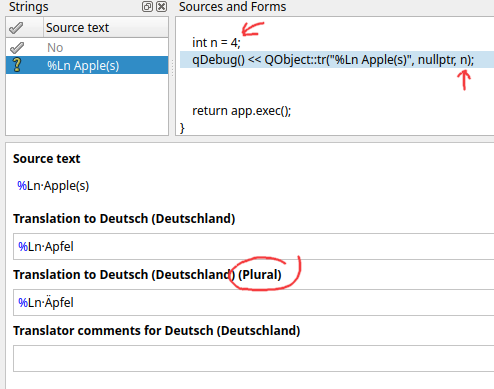
As you can see in Linguist, you need to provide a singular and a plural string (possibly third string, language dependent). The value for n will then control what will be shown at the time. In the above image, there's a happy little umlaut over the A for the plural case. Which is the correct plural form of "Apples" in German.
If you're wondering why in the display string I'm using %Ln instead of %n or a %1, we'll get to that later.
Other Strings
The other type of strings that we can have in our app is not necessarily user facing one's. In regards to translation, there's not too much more to talk about here, except that it's possible to accidentally forget to mark a string for translation. Where it could "slip" through. That's bad.
A way to remedy this is having you (the programmer) explicitly mark all of your strings as translatable (with tr()) or as literals. This is something that we did at a previous place that I worked. The programmers prior to my arrival never intended the product to use multiple languages, so they never bothered to wrap any of the strings in tr(). This was quite the headache for me to go and audit the software to figure out which strings needed to be translated, and which ones didn't.
There are two macros that you can define at compile time to help with this. QT_NO_CAST_TO_ASCII and QT_RESTRICTED_CAST_FROM_ASCII. This way, compilation would fail if you did anything like this:
And you would need to do this instead:
This will force you to mark what you want translated, but also what you don't.
I will note that this can get quite pedantic and annoying, but at this place that I was working at the time, it did help the other programmers on the team to mark their intentions for string usage. If you want to read up on QStringLiteral woboq has a nice article here, but it is also fair to note that there are others who aren't fond of it.
In my personal opinion, I would not like to force it for any new project I was working on as it can be frustrating. But when you are coming into a code base that is an absolute mess, needs refactoring, and you want to ensure others on your team be explicit with their intentions, requiring QStringLiteral will help.
Localization of Resources
It is very likely that you might have some resources in your app (e.g. an image) that you can't use in another language. Take for example the title screen of the first Pokemon game. It was drawn in Katakana for the original Japanese release. Though it needed to be in English for the US. Seeing as this asset is an image and not some plain text, something more needs to be done.
You might be thinking you could get away with a qsTr("logo-en_US.png") in your source. Then swap that out with, say, logo-fr_FR.png with Linguist. While that does work, it's a bit clunky. There's a much better way by leveraging Qt's fantastic resource system.
When I was trying to work on the Japanese translation of PSRayTracing, I was facing a bit of an issue. The fonts weren't legible at all, they were too small. The glyphs for latin based scripts are pretty simple and can be rendered quite tiny, but still be legible. Using the same font size for east asian languages (E.g. Chinese, Japanese, Korean) is not really doable. Take for example, one of my favorite Kanji: 鬱 (which has the meaning of gloom & depression).
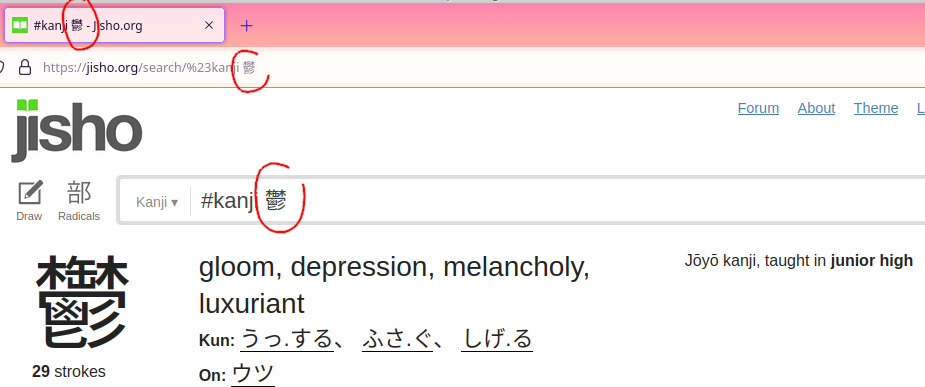
You're not able to discern many of the specific strokes when it's tinier. Yes, this is a more of an extreme example, but there are quite a few Kanji's that are very similar. We need to make the text larger here.
And how was this fixed? Since PSRayTracing's GUI is 100% QML, loading up a different, language specific qtquickcontrols2.conf file at startup is what was done. Normally I use a font size of 12 for the app, but bumping it up to 15 is good. First, I made a file called qtquickcontrols2_ja_JP.conf, with the Japanese specific adjustment:
Then in the main resource file, it is added in, but with a Language Selector. Don't forget to alias the _jp_JP variant to the original.
Now when Japanese is loaded up, the font size of the application is larger and more legible.
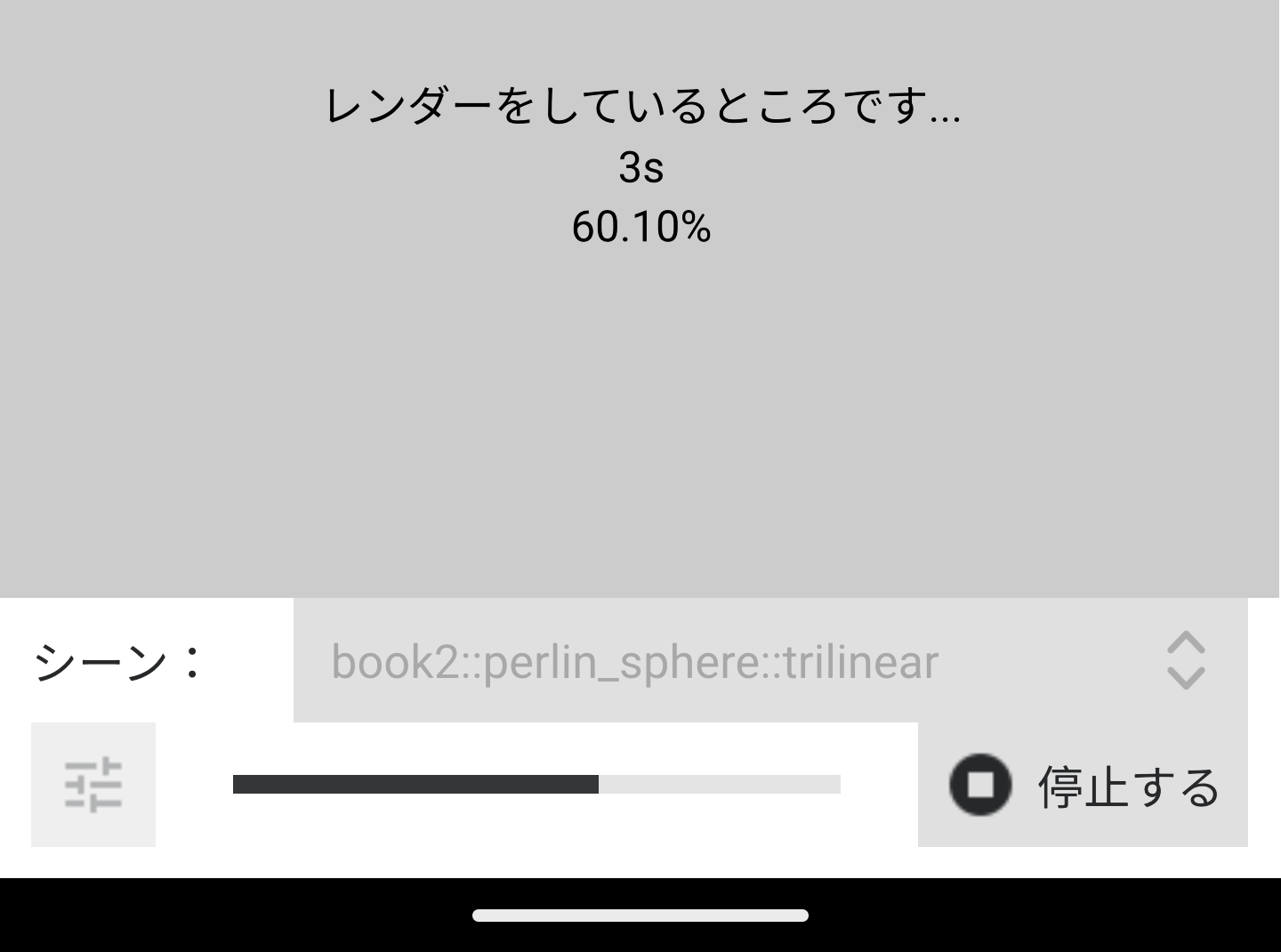
Going back to the original example of localized logos, you can use this feature to swap out images when a different language is detected. Should be simple enough.
Localizing Numbers
This is a short topic to cover, so there's not too much to mention here, but I feel it's important.
Have you ever seen the inside of a German store and thought, "Why are the commas and decimals in the wrong places?" Well, they're not. Some countries just have a different way of writing numbers. In places such as Deutschland (compared to America), the comma and decimal are swapped.

When we write software we should be aware of these differences.
To account for this In Qt, where you would use %n to display a number, use %Ln instead. Qt. will take care of the rest at runtime and format your number for the proper locale. Microsoft's Number Formatting document gives a good overview on this topic. And if you want to go deeper, read the Wikipedia article on the Decimal Separator. Please, use %Ln by default. You'll make your life easier and others will appreciate it.
CMake Setup
IMO, setting up translations is a bit easier in qmake, but I'm using CMake, like the rest of the C++ world. So let me show you how to set that up.
And that's it! I very much recommend reading the documentation page for qt_add_translations() so you can better understand what is going on. For instance, I was having some issues with the translation modules (the .qm files) not appearing to be generated or embedded. Reading the docs, I found out manually specifying the release_translations target as a dependency of myapp did resolve the problem:
Translation modules can also be generated directly from the lrelease tool without having to rely on the build system. I rarely use it directly, so I'm going to keep it out of the scope of this document. You can read more about how to do this over here. For now, just pretend that the .ts → .qm step is magic.
Updating Translations
So far I've made mentions of these .ts files, but I've not really told you that much about them. They are the core of the translation system. They are generated from Qt's tools by scanning your source for the tr()/qsTr() calls and then placing the strings into the aforementioned .ts files. This is done with the lupdate tool. From there, you hand the .ts files to your translator, tell them to get a copy of Linquist, and then get to work. Under the hood, these files are actually XML:
As you can see, there's a lot more than the simple "String A equals String B". Translations can be marked as incomplete, disappeared, have a source, etc. These are visually displayed inside of the Linguist tool. This becomes super handy for tracking down the context of a translation or seeing if something has changed.
With the above CMake command of qt_add_translations(), lupdate should actually be invoked during build time. For PSRayTracing, I initially was having some trouble with it for some odd unknown reason (that I'm no longer able to repro). In case you need to, manually invoking lupdate is fully possible. Please check the docs here on how to do it.
"Installing" a Translation (a.k.a. Changing Languages)
Having a translation is no good if you can't actually use it. In Qt's terminology, this is referred to as "installing a translation". But for the rest of us, we simply refer to this as "setting the language". When generating a new project in Qt Creator, this code should come default, but if you happen to not have it, here it is:
This should go inside of your main() function, right after instantiating the QApplication/QGuiApplication instance, but before any UI is shown. In summary, this will check all of the languages that you specified (on your system) as desirable. The first one it finds, it will use that translation. And if it doesn't, welp, then you're stuck with whatever is shown inside of the tr("...")/qsTr("...") calls.
I think it's fair to point out as well that some others in the Qt world aren't fond of the above block of code being the default "load translation" block. This blog post by KDAB illustrates the issues and provides an alternative: https://www.kdab.com/fixing-a-common-antipattern-when-loading-translations-in-qt/
It's fully possible for the language of your app to change on the fly too. Looking in the docs for QEvent, there's an event type called QEvent::LanguageChange.
While this might seem like a cool thing to support, I don't recommend it. It could be handy during development. For example, in order to figure out how all of the UI elements will fit together to support multiple languages. It will put a lot of stress on you, the programmer, to make sure all of the UI elements are being correctly updated. It would be best to handle the QEvent::LanguageChange event just to let the user know they should restart the app to see the language changes take effect.
Fudging a Locale at Runtime
Normally for testing I'd recommend that you change your device's (or users') locale. But for development, this can be a pain. It's easy on Android/iOS/macOS where you can toggle this in settings quite quickly. On Linux, you have to log in and log out again. It gets tedious. But there is a quick and dirty way to change your app's language: Just force the locale at runtime. Here is how to do it in a single line. Put this right at the top of your main(), right before instantiating the QApplication:
I am aware of setting the LANG environment variable on Linux devices, but in my experience, that hasn't worked well. The above has been way more reliable for me and works on all platforms.
Note that this alone might not change the language of your app, that is if you're using the "translation installer" from the above section. That is because what you (manually) set the locale to be, might not exist in the uiLanguages (despite there being a translation module). But there is a quick fix for that:
When a new QLocale object is created, and a locale isn't specified, it will use the default that's set. Make sure to undo these changes before deployment.
Okay, that's not so much "runtime" and moreso "hardcoding", but I think you get the idea here. If you want you, it's possible to make something more complex that could be set at runtime, with a configuration variable (e.g flag at launch). But I leave that as an exercise for the reader.
Misc. Qt. Stuff
And now, just some other random things I'd like to get out of the way:
- Not all languages operate on a Left-to-Right system like we do in the West. There are many popular languages such as the Semitic family that use Right-to-Left reading systems. Qt has built in functionality to help you out with that. Personally, I've never had to use it, but with the growing importance of the middle east region don't be surprised if software starts being translated there more and more often, such that UIs need to accommodate this.
- Need to give someone a
.pofile (another industry standard) instead of a.tsfile? Qt has you covered. There is a tool that's shipped with Qt calledlconvert. IMO, it seems to be only semi-documented, but it will let you convert between these two formats. It's invocation is super simple:lconvert myapp_en_US.ts -o myapp_en_US.po lconvert myapp_de_DE.po -o myapp_de_DE.ts
- I do love the linguist tool, but it does have one major deficiency: newlines and HTML are not rendered. This would be SUPER helpful for any translators. In PSRayTracing, there are a few places where I have multi-line strings. In Linguist, they only come out as
\n. And in another section, I use some light HTML for formatting (including escape characters); none of this is rendered out. Get ready for you and your translator to pull each other's follicles out from your scalps. - If you change a single source string, it's going to cascade down the line to all languages. This is an absolute nuisance. Especially if you had something misspelled in your source language. IIRC, Linguist can detect if a source string changes. But it might also say that you have both an obsolete string and a brand new one.
- And you're going to have to notify your translators of the change anyways...
- Your app might have a base "English Translation" despite the native tongue of your app being English. If you generate a new project in Qt Creator the wizard at some step will ask you about a Translation. It's wise to put this in, despite that your source strings are written in English
- One of the benefits here is that this helps you handle plural forms mentioned above
- This "base translation" could serve as something you give to translators for brand new languages. E.g. Linguist lets you add comments to each string, so putting them in the "base English" translation can be helpful.
- Another thing is that in your source code you could do this:
tr('hello-msg'). In Linguist, havehello-msg→Hello Worlddefined (for example). So now all of your "truly user facing strings" are defined in.tsfiles; not in source.
- EDIT 8/12/2022: Reddit user /u/disperso pointed out that
QFileSelectoris something worth mentioning too. It's something that I haven't personally used yet, but gleaning from the docs, it does seem very useful. It can be used to pick the correct variant of a localized file, depending upon the current application's locale. Please go read the docs for now to use this one.
General Principles and Things I've learned
Now, we've come to the time in the blog post where we let go of Qt and I'd just like to share some of the things I've learned while translating existing software. But also making new projects translation friendly. Keep in mind, this is not a rulebook; simply a guideline.
Keep Your Content Organized
Put your localized content in an i18n/ folder. From there, if you want to create further subdirectories for each locale (e.g. i18n/de_DE/, i18n/ja_JP/ etc.), you can do that too. Keep your projects organized.
German Will Break Your Layout
In fact, I've found both French and Russian to be just as bad. I'm having some trouble trying to find screenshot examples of this. But it is very well known that the German language can have some quite long words. It's not uncommon when you plug in a non-English European language for your UI to completely break. I got pretty lucky with translating PSRayTracing where I didn't have to adjust the UI that much. I only had two big breakers:
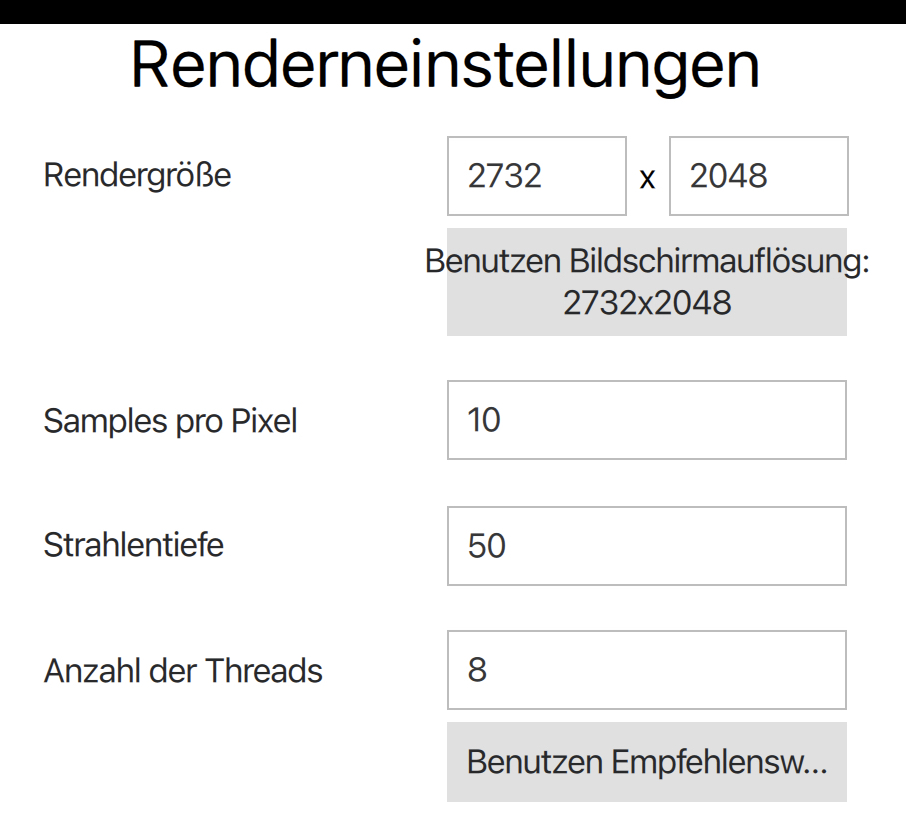
Both of these buttons' text were easily fixed by inserting newlines after Benutzen. This is something I've commonly seen. Another common tactic is to also provide abbreviations.
Chinese, Japanese, and Korean Glyphs are W-I-D-E
These are referred to as the "CJK Fonts". For computing these have presented many issues compared to simpler Latin/Cryrlic based systems. One thing I don't see many others talk about is how physically wide their glyphs can be. This is also coupled with having to make the fonts a larger size for legibility reasons. See the example of 鬱 above as to why.
Because of this CJK can easily break layouts. Here's what the Japanese translation did to two of my buttons when plopping in the initial translation:

That first button's text doesn't have enough padding/margin on the left and right. And the button below has gone off into ellipsis land... Even at the same font size, the CJK glyphs are sometimes nearly twice as wide as a Latin character. Take a look at this example of writing "Hello" in Japanese. こんにちは (konnichiwa) uses the same amount of glyphs but it is significantly wider.
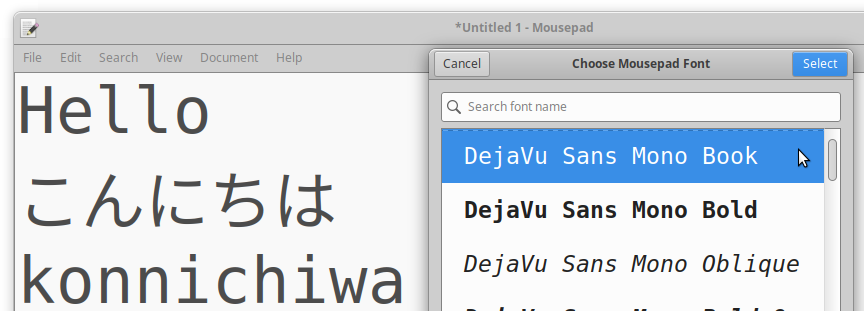
Going to a non-monospace font, it's just as bad.
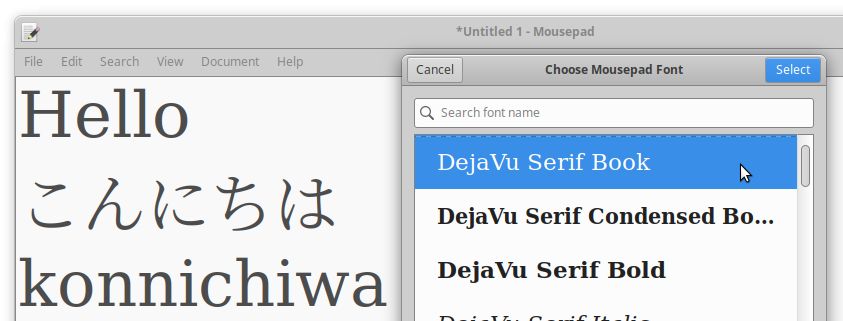
Prepare for CJK.
You could also lump Cyrillic based alphabets into this group too, since their characters are more "blocky" than Latin based scripts. But you can make the glyphs smaller. Not as bad as CJK.
Software Isn't Immune to (Geo)Politics
The vast majority of people who read this article are probably living in developed western countries; which tend to get along better with their neighbors. Other places where software is sold, this isn't always the case. It's likely that you might need to tune your application to fit within the politics of a certain region.
A well known example of this is how Google Maps will redraw the location of borders, depending upon which country you're accessing the service from. On the silly side there was Hans Island between Canada and Greenland (Denmark), chronicled as the Whisky War. Eventually resolved this very year (2022). But on the more serious side there are active (somewhat hot) territorial disputes between India and Pakistan. If you had to make a map, who would you show this belonged to?
Another example of changing software for different locales: censorship. When Team Fortress 2 launched in Germany, Valve had to censor out the blood and gore from the game despite its highly cartoonish nature. Mega Man Zero, a beloved game from my childhood, was toned down for the International (non-Japanese) release.
If you're also thinking about translating a specific piece of software to one language because it's a lingua franca across multiple markets, that might not always be the case. This BBC article covers it pretty well, but German (and Latin) used to be one of the languages that scientific papers were published in. There were even scientists and engineers who attend German night school so they could better understand what their peers in Germany & Austria were doing. Welp, two world wars changed that. In the U.S. we were instructed to not speak the enemy's language. Scientists from Germany and Austria were boycotted from conferences and journals. I fully expect similar things to happen in the near future once again.
The quick and skinny guideline here is:
- Some countries don't have the same laws as us
- Some countries don't have the same ethics as us
- Some countries don't recognize other countries. Flags, languages, ethnicities, borders etc.
- Some countries are actively (and passively) at war with others
- What is acceptable can change over time due to politics
You're Going To Find Weird Things
This can be true of anything in the sciences. Maybe I'm biased and I feel like this comes up more in the software realm. Or at least we question these occurrences a lot more since we know (or hope) that these systems were built by other rational human beings. Not some freak manifestation from the universe.
When I was working on the Japanese localization of PSRayTracing, I had the resource system use a modified qtquickcontrosl2.conf if Japanese was detected (see in the above section "Localization of Resources"). This was in order to make sure that all of the text was nice and easily readable. Everything was working fine on Android & Linux. But testing it out on macOS and an iPad, it wasn't working; i.e. the default qtquickcontrols2.conf was being loaded despite setting my system's language to be Japanese. I was seeing Japanese strings show up in the app, but with a smaller font size.
I filed a bug report (to Qt) for it. And after about two hours of making a small repro project, I found the culprit. Qt was reporting my system's locale as ja_US. Yup, that's something I didn't expect. A locale of "Japanese (American)". I have never seen this locale ever in my life. I've seen things like de_CH for "German (Switzerland)" or de_AT for "German (Austrian). But never ja_US.
A Google search for "ja_us locale" only turned up one a single relevant result; another person asking "Have you ever seen this before?" Well, it turns out that this sort of thing does actually exist, and with a significant amount of users. Unfortunately, this is something that does break the app. The language can be loaded, but not the locale specific files, where this is only hhappening on Apple platforms. I don't think this is the fault of the folks at Qt, but it's something that they (now) need to accommodate for. Such is the life of people who make cross platform stuff.
¯\_(ツ)_/¯
Ensure Your UI Layouts are Flexible and Adaptive
I'm talking about from the get go when you first plan out your UI. It will save you a lot of pain and frustration in the long run. It will be hard (but not impossible) to go back and fix poorly constructed UIs. Remember that design is one half, implementation is the other.
When I first worked on the "Render Settings Form" for PSRayTracing, I envisioned that its layout would always work well as two columns.
labels on the left
[____ forms on the right____ ]
This worked well on all the platforms. Until Japanese & German strings broke the layout, partially making it unusable. To fix this, I deployed a layout pattern I've seen in other places:
labels on the top
[___ forms underneath ___]
This is something I initially wanted to do for the initial release of the GUI, but I was way too exhausted and wanted to work on other tasks. And now that was coming to bite me back in the butt a bit. But alas, it actually was a quite simple change. The real meat of it being about 3 lines:
The full change is closer to 20-ish lines, but that's to make sure everything looks and feels nice:
Feels Great.
And as a last bit for this section: avoid using "fixed sizing" and "absolute positioning" for UI elements/layouts as much as possible. These will burden you later on since you might tailor the look and feel of something for a string in English, But when that string is now 2.3x larger, things will go bust. I've been on projects where absolute/fixed UI elements were so baked in, we couldn't change them out. We had to keep on running back and forth with the translator to get shorter words.
Put Your User Facing Messages in One File
Alright, it actually might be two files. One for C++, the other for QML. Or if these files start to get super large, feel free to break them string down into categories and put those into more files. The idea is here to make sure strings aren't spread across too many spots. I've worked on projects where user strings were all over the place. Lots of duplicates. It was a pain to coordinate and make sure everything was correct.
If you want to see an example of this, check out the full Messages.qml file from the PSRayTracing repo. The idea is that you have every user facing string be its own read-only variable that lives in your Messages.qml/Messages.cpp file.:
Excerpt from Messages.qml:
Benefits of this:
- Everything is in a single place (or only a few)
- Makes message/string reuse much nicer
- Refactoring is a breeze; renaming a variable is much easier with tools than changing a string in 12+ locations
- Don't need to re-enter the same translation 12+ times over
- Changing a translation is quick
The big-sad from doing this is that you lose context of where a user message is located. I'm talking about in Linguist. The .ts files contain annotations of where in the source code the string is located. And in Linguist, that source will be brought up to show you the surrounding code for that message. But IMO, the benefits far outweigh the downsides.
Testing Will Be A Pain
All done with running a smoke test on your application? Ready to approve it for release? Good, now make sure it works the same in German. The same in French. Perfect in Japanese. Do Polish. Latvian.
Be ready to iterate n amount of times. Where n is how many languages you wish to support. This is going to be QA's problem.
Oh, did QA find a problem for one language? Good, now fix it.
Oh no, this means you, the developer, now needs to fix the UI for that language. But now you need to run through n - 1 languages to make sure nothing else is busted.
Ah, you've verified that it's working well for m different languages (where m < n). What's that? For language m + 1, now something adjacent is busted. Fix that too. And re-verify all n languages.
I think you can get the picture here. You will have to iterate a bunch of times, over and over, and repeat yourself, over and over, just to make sure things are good, over and over.
Which brings me to my next point...
Users Will Break it in the Wild
This is another one of those things for software in general, but I feel the need to give it some spotlight here.
Right after I published the most recent release of PSRayTracing on Google Play, I actually did not expect anyone in Germany or Japan to download the app and take it for a spin in their native tongue. Lo and behold, sooner than 12 hours after pressing "Release" someone in Japan downloaded the app, then posted a screenshot where I could see the layout was broken. In fact, they posted two screenshots!

After the weeks I spent making sure that this layout worked on different devices in different languages. Someone just goes and borks it up in a short amount of time.
ಥ∀ಥ
In all seriousness, I thank them for posting this so I can go and fix it.
Don't Use Any Machine Translation
I hope this is an obvious one. Do not do it for any UI controls/messages.
Okay... I actually did for the "About" pages in PSRayTracing, but I at least added a notice that was. The rest of the UI was translated by hand and I verified this by checking other (translated) apps that exist in the CG realm. In my defense, my German and Japanese language skills aren't up to par to translate a technical block of text like that. Just please don't do this if you have an actual commercial project.
I did break my own rule here and I am sorry...
The Worst Translation Project I Ever Worked On
Oh boy. It's time for "Developer Blog Post Rant Therapy Time". Gather round now boys and girls and let me tell you a scary story. It is Halloween season after all. There is nothing of technical importance in the words below. You can spend your time reading this if you like a good cautionary tale. If not, feel free to skip this section.
At a previous job, we were developing a product that had a fixed display size. When I first got onto the project, it was already well behind schedule. The code was also an absolute mess. If I had to give an estimate, I believe that about 90%+ of it was written by people who had never worked in Qt before, and these people were no longer at the company. Unfortunately, it was my responsibility to fix this.
Bad things were done. Such as never marking any strings as tr(), using fixed size UI elements, layering dialogs on top of dialogs (that stole focus but were not closable), absolute positioning, copy-n-pasted code, no documentation/comments... This was violating nearly all of my guidelines listed above. While working on fixing bugs, I made sure to spend a little time making things more solid, flexible, clean, etc. The big one for me was marking those user facing strings as tr() so this product could be sold in places other than the English speaking world.
During this initial time there, I remember once chatting with upper management briefly, "Yeah, this product can actually handle multiple languages with ease. Including ones such as Japanese. It's going to take some work though to get it done. I'll send you a screenshot as proof." Which I did later. They responded in kind with a "Thank you. This is very valuable information for us and the future of this product."
A few days later during the weekly team meeting, the project manager wanted to talk about one more thing before ending; he seemed a little irked about this too. For this story, I'm going to refer to him as "Mr. A".
While looking at me, kinda upset, Mr. A said:
"Someone talked to upper management, saying that it's possible to translate this into multiple languages for release! Now they want to know how feasible this is to do!!"
I replied:
"Yes, this is fully possible. About a month and a half ago I started to go through and mark all of the strings that we need to translate. I would say that I've gotten a good 90% of them so far. The last 10% might be a bit more tricky since they show up less often. We also need to put in some localization infrastructure, but that should be simple and I've done this before."
My boss (not the same person as Mr. A) concurred that this was taking place and he thought my assessment and general outline was correct. Also stating he thought I should be the one leading this undertaking. I continued to explain a little bit more about the process of translating Qt based software. Some questions were asked of me.
Right before the end of the meeting, Mr. A snapped in:
"Alright, I'll tell management we're going to work on this. And Ben, if you refuse to do it, then I'll find someone else who will!!"
Me:
Umm, I said I want to do it, and I already have been working on it."
After that exchange I was a little bewildered. I huddled up with my coworkers, asking, "Did Mr. A threaten to replace/fire me? For thinking I was going to refuse to work on a project, which I've already started to work on?" My coworkers were quite confused too at Mr. A. You can probably guess what kind of person he was like to work for.
Later that day, Mr. A came up to me at my desk. Very nicely, like a begging puppy dog, asking me if I'd be willing to take the lead on the translation project. I said "Yes". It was something I wanted to do. He said that we would be targeting five more languages, all western European.
A few days later he sent me an email asking me about a time estimate for this project. I quoted him that it could be 6 months. He was quite upset in his response. It honestly wasn't an overly complex product. I really thought if I was given pure laser focus and all of the tools/resources required, this could be done in less than 2 months. I gave him this absurd estimate for a few reasons:
- We still haven't identified all of the strings
- We still need to add in plumbing for translation to work
- We need to have people translate the software and give it back to us
- Non English input it something we need to design for
- The UI layout is very English specific; other languages are going to break things and we'll have to fix the layout for all six languages
- There is going to be much iteration for development and testing
- We are going to discover problems we did not know we had
Another trick that I've learned is if you tell someone it's going to take 8 days, but then get it done in only 3 to 5, they'll think you're amazing. But if it takes you closer to 8 or 9 days (i.e. unforeseen issues), you're good at giving estimates.
But there is one other key reason I gave him the half a year estimate (and I didn't tell him this):
I knew at some point Mr. A was going to tell me to put the translation project on hold, but blame me if it wasn't done in 2 months. Irregardless of him telling me what to work on, and when. The extra 4 months of padding wasn't there for anything actually related to translation. I added it in because I knew the (sad) state of this product and how he liked to manage.
The next week I formally started on the translation project. Put in the support for switching languages, tracked down about 98% of all strings, adding in country flags, gave Mr. A the .ts file to hand to translators, etc. Things were going well. About 3 weeks into it he told me to fully stop working on it as we had other bugs that required more attention for an upcoming release.
-_-
And well, the translation project then languished for the next 4 months. The only thing I could do is mark strings as tr() in preparation for when he wanted to pick this back up again.
After a long while, during the weekly meeting, out of nowhere Mr. A asked me:
"Ben, what's the status of the translation project?"
I replied:
"We haven't done anything with it. I sent you those .ts files three months ago. Did you give them to the translation firm? I never heard back from you."
He spat back:
"WHAT?! We're already horribly delayed with this product as it already is!! This is a core selling point!
After this, I did remind him that he told me to stop working on this portion of the product months ago; I don't think that he liked that I brought it up. He asked me what we needed to do. The difficulty of getting this done had also increased since more features were added to the product. He didn't like this, but he told me that adding those extra five languages would now be my 100% full focus. It became 80% of my focus.
Then he demanded I do something I dread: "Ben, translate the UI to French using Google and plug those strings in". Oh my, do I hate this:
- Those strings are not going to be accurate at all
- Because they are not accurate, we won't have correct sizing for the UI Elements
- It's a waste of time because of the two above points
- It would be better to just wait for the real (correct) French strings to be in
- My biggest fear was someone in upper management saying, "Let's just ship the product with the machine translated French; it's good enough"
I tried to push back on this, but he was adamant that I must do this. He thought it was vital to the success of the project. The rationale: "We'll be better prepared when we get the real French in". When the actual translation came in from the outside firm, this was not the case. I had to spend another week re-fixing the UI for the correct French.
(╯°□°)╯︵ ┻━┻
There was one other thing that felt really odd to be about this translation process too: the firm that was doing our translations would only accept the strings in an Excel sheet. Now, this is a perfectly valid way of doing translation. But, as mentioned way above, there are industry standards such as .ts and .po which are used specifically for the realm of software. Mr. A had told me he worked with the firm before on other projects elsewhere. That they would give us a "Certificate of Translation" to prove that our software was properly localized. I asked Mr. A if I could lookup the firm's name online and their website to see what they accepted, as I found it quite odd we couldn't give them the .ts file directly.
Mr. A. refused to tell me (quite defensively) and told me just to send him the Excel file. He did inform me that this firm would first take the Excel sheet and run it through a machine translator then have a human look it over. He also reiterated that the "Certificate of Translation" was highly important. Coupled with not accepting .ts and .po files something about this did not seem right to me. But alas, I was at his mercy, so I had to comply.
We eventually received the German translation from this firm. In short, it was an absolute mess. Let me tell you about the most egregious one...
Remember my example above of the word "no" in German? Let me repeat myself: The word "no" doesn't always translate to "nein" in German. For some cases where there is a zero quantity you need to use a separate word. "Kein". For example, in English we might say:
I have no apples.
In German, the correct translation is:
Ich habe keine Äpfel.
I think you might be able to guess what word this "certified" translation was using. They were using nein and only nein. EVERYWHERE. Where kein should have been used, nein was there sitting in its place.
This was crap. I was able to find other problems with it too. I even sent it off to our distributor in Europe. As he was more experienced with the technical/scientific German that was needed; I was not. He said that about 40% of the translation was incorrect. Even pointing out examples of other localized software that had correct German translations. I very much agreed with him.
Our distributor (separate from the translator) corrected a lot of the poor German. This should have never had to be done. I eventually gave this corrected German back to the translation firm. They weren't happy about receiving this news and pushed back with how they were in fact, actually correct. Something about this firm and Mr A.'s obsession with the "certificate of translation" seemed incredibly odd to me. But there was nothing that I could do. I had no power to make decisions where I worked.
After German and French, I had to add in the rest of the other western European languages. I mostly ran into the same issue over and over again: a word being too large for a UI element, thus breaking the software. Rather than actually fixing the UI's layout and positing code, Mr A.'s instinct was to ask if we could just abbreviate the word. Unfortunately, this is what ended up being the solution so many times over. Thus littering our software with way too many acronyms and periods than I felt comfortable with. I also had to run back and forth with the translators a lot when something didn't fit.
Once I was on the last language, I got word form Mr. A. that upper management wanted to sell the device in eastern Europe as well. This was not too much of a problem for languages that used a Latin based alphabet. Once again, it was more layout tweaking and "abbreviation abuse". But oh boy, the Russian translation horribly broke the layout. I made a brief mention above of how Cyrillic scripts are quite "blocky". It's because their glyphs can be quite wider than Latin characters. There were places where abbreviations were a no-go, so I actually got to properly fix the layout code in some sections.
At the end of this arduous process. I was proud to parade that this product could be sold all over Europe in many different locales. Remember when I told Mr. A that my time estimate for the project was half a year? From the initial work of collecting strings through plugging up the last glitches from Russian; it took about six and a half months.
For those of you who spent the time to go through and read my story above, I thank you. I hope you take it away as a cautionary tale of how not to do a localization.
Final Words
There is one last statement I'd like to leave you with. It can apply to any project:
Good developers don't just ignore these things and only listen to management; they raise issues before things get out of hand. Likewise, good managers give their developers the time, space, and trust to fix these problems before they become bigger troubles. This is not limited to code and layout, but should also take in account UI, UX, and different cultures. We are making things for human beings; other people who might be very different from us.
Lastly, I'd like to thank the folks at Qt who keep working on all of the bugs I file. I like to make a special mention for Joereg Bornemann who helped me with a false alarm report I made. Credit to the rest of you too.
Please take great care in everything you build, for everyone else.
![]()
Update Feb 26th, 2022: A software engineer from the Qt company reached out to me after reading this article to acknowledge some of the iOS issues. Saying that they have been know but weren't tackled yet due to time constraints. Links to tickets were sent to me and I'll be provided them at the end of of the "Tart Apples" section. I thank them for informing me.
Recently I started a new job, where I was working on an Android & iOS app that's written in Qt/C++. While I have loads of experience with Desktop Qt (the classical Widgets API), I'd never really made anything practical for Android and iOS (QML/Quick API). In order to get some better practice with trying to make "fully cross platform mobile and desktop" software, I thought it might be worth my while to make a small app that achieves this in Qt. And it could act as a starting point for others showing how to structure such a project. Qt makes the bold claim of "Code once deploy everywhere." I really wanted to test that claim. I did and I feel it's accurate.
I want to note that this blog entry is not meant to be a complaint about Qt (okay, maybe a little). I really do love the framework. I Wouldn't have tried to make a career out of my knowledge of it if I did not. But I do want to note that there are parts of it where it can get frustrating. I hope that this lengthy post can help someone else in the future who's thinking about using it. Or even the issues described here will be resolved and these words become horribly out of date ramblings of an era long gone.
If you want to simply play with the app, It's up on Google Play over here. It does run on iOS, but there is no page in the Apple App store; details as to why are far below. This is fully open source, so if you want to peek at the code, you can find it here
A Friendly UI for a Past Project
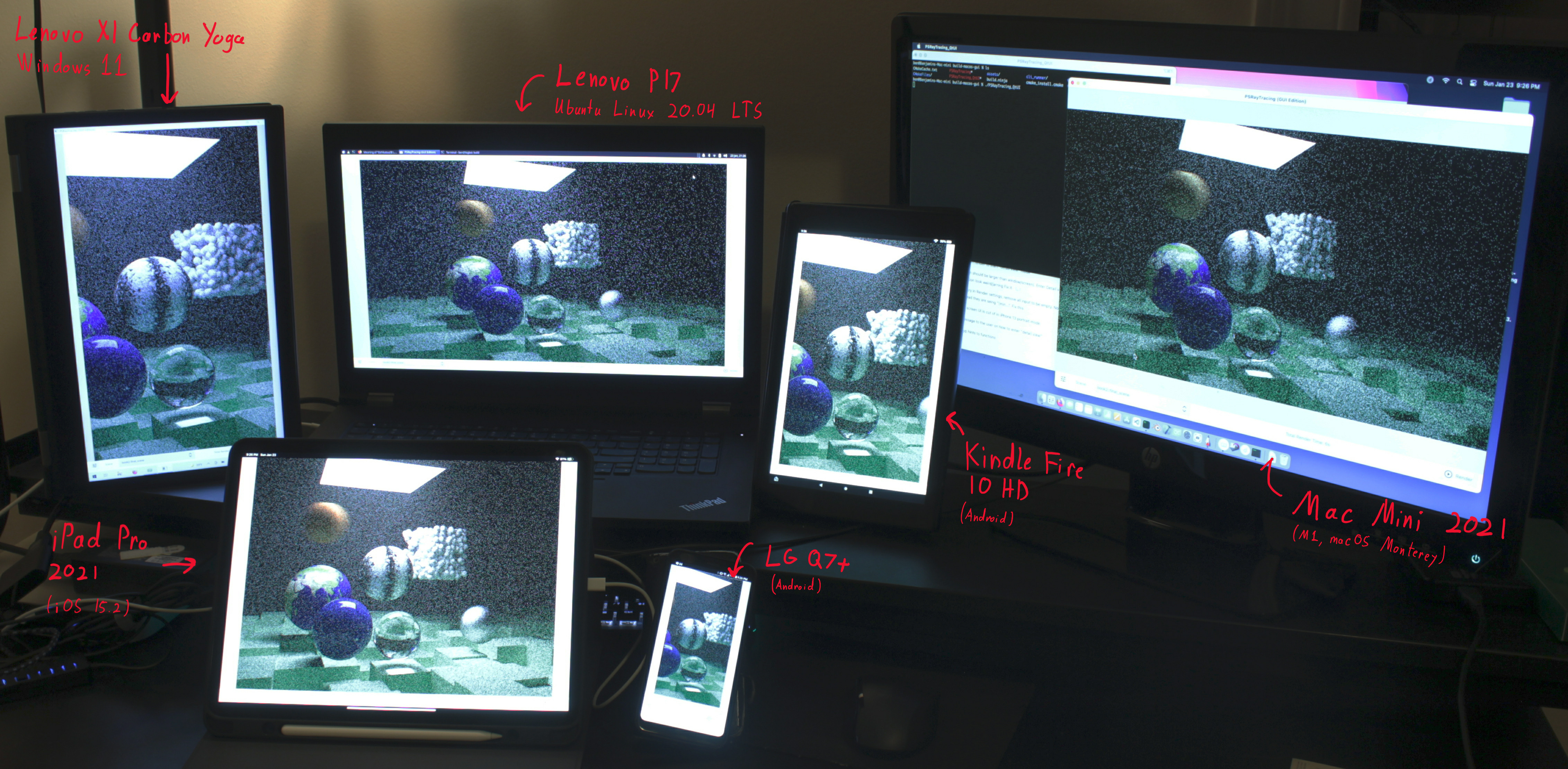
Yet again, I find myself not able to escape working on the PSRayTracing project I first released about a year and a half ago. While I'm very satisfied with how the code performs on desktop devices, I was really interested in seeing how well it would work on mobile and tablet platforms. I have a Kindle Fire from 2020, an LG Q7+, and recently had to purchase an iPad Pro (M1) for work purposes. PSRayTracing, being very vanilla standard C++ (except for third party source) I know this should compile and be able to run on Android and iOS with no problem. Moreso, the issue rests in providing a good way for someone to use this when a terminal window isn't really available. Writing a Qt based, Cross Platform GUI front end to PSRayTracing is something that I thought would serve my purposes well.
I've been dabbling with the Qt framework for about 8-ish years so far. It first started with me trying to make animation software back in university. It became something I could slap on my resume when looking for required internships. After graduating, I still spent a considerable amount of time on the framework. Beginning with my second full time job, I became a "Professional Qt Developer". I still fiddle with it all the time for my hobby projects.
I remember the jump from Qt 4 to 5 was pretty big. I also remember when Qt 6 was formally released only a little more than a year ago. At that time, Qt 6 wasn't on feature parity with the 5.x series. IMO, it was missing some critical stuff. Then later on 6.1 came along. It was more put together, but missing other components I wanted (e.g. Charts). But in the recent past, 6.2 came out. We were promised that it is now fully on the level with the latest from 5.15. And, it's an LTS version too! So I thought this would be a great opportunity to take out 6.2 for a real test drive.
My goals were this:
- GUI frontend that works on Windows, Mac OS, Linux desktop, along with Android and iOS. With a seamless experience between everything
- Write as little platform specific code; or none at all
- Be able to profile performance of the mobile devices for PSRayTracing
- Try not to break existing things
I will say that I was able to achieve all of this. But like with any project, there were some bumps along the way. I'm still going to be using Qt after this; this blog post is not meant to knock it down, but to catalogue the hiccups I went through and you may have to yourself if you go down the Qt path.
If you ever played with PSRayTracing prior to this point, it was something that you had to download, compile, and use in the command line. I didn't want to break this way of using the program as it is very nice to have a headless mode, especially for testing, so some refactoring was in order:
- Pull out all of the rendering logic into separate component; aptly named the "Render Library"
- Take all of the leftover
main()code (argument parsing, text UI progress bars, etc) and put it into a separate sub-project. The "CLI Runner", which uses the Render Library - Make a new project called "Qt UI" that is the fancy pants graphical way to interact with the Render Library. It would serve all of the functions of the CLI Runner (e.g. scene selection, thread count, resolution, etc,) but provide a "more safe" interface. For example, it would stop you from entering in a resolution of
-41xPopKorn. It is to also have its own image viewing component. That way you don't have to open the generated image in another program. Qt provided me all of the building blocks to make this
The existing CMake project structure that I had at the beginning of this was easy to leverage. I first made a top-level CMakeLists.txt file. From there, created a render_library/, cli_runner/, and qt_ui/ folders, all with their own individual CMakeLists.txt
One of the other important things was to make sure that people didn't have to build the Qt UI if they didn't want to. Since this should be able to run in a headless mode, you shouldn't have to need the (quite hefty) Qt framework installed on your system to get going. Luckily, this was easily achieved by adding a CMake build option, simply called BUILD_QT_UI. By default, it would be set to OFF. Then at the CMake configuration step, you could flip this on.
"But wait! In the Qt creator, if I specify I'm building for Android or iOS, I still need to manually flip this flag!!" I'm a fan of automating away intentions and reducing as much work as possible for others. I needed to wipe out my build folders a lot during this process, so any configuration flags I had would go bye-bye. So if I was building for Android or iOS, I wanted it to build the Qt UI by default. When configuring the builds for these environments, it's pretty simple to detect. Android is easier, iOS is a bit more involved, but here is the snippet I added to check for a mobile environment:
I gave a thought to trying out meson, since it seems to be the latest hotness in the C++ community for the past few years. But seeing as I already had a CMake setup going and I wasn't too sure of the Qt (6) support for meson, I thought it would be best to not change a horse mid stream. I'll keep it in mind for a future project.
It's also possible that I could have done this Qt only portion in qmake (Qt's own home grown build system), but part of me feels that this tool is on the way out. For Qt 6 they moved their build system over to CMake and have added much better support for Kitware's tools. Though at times, I do feel that the CMake support is not fully there. CMake also did require a lot more "manual specificity" with options for iOS, which was a real pain (and should just be set by default). More on this later.
Others in the Qt community have the strong desire to use CMake for their projects, but can be a pain when trying to couple it with Qt. A good example of this is QtIosCMake. I was tempted to use this for my own project, but I wanted to see how far I could get without bringing in third party CMake scripts. I'm glad to report that I was able to do everything with "Vanilla CMake", sans the stuff provided by Qt officially.
One other thing to note is the render library portion is built as a static library. This was done because it makes distributing easier. In a perfect world, I would love to have it as a DLL/dynlib/.so but knowing how much of a pain it can be to deal with dynamic libraries in C++ land, especially when it goes to multiple platforms, I opted for the static library route instead.
Now that my CMake structure was all good, it was onto the next step: code refactoring
Refactoring out to "Render Library" and "CLI Runner"
Since I planned well last time, the existing structure of PSRayTracing made this fairly easy to do. When I made the first version of the project, The main() function was only about 150 LoC long. It had a mix of instantiating render logic objects such as the RenderThreadPool and RenderContext, but also the user interface components like util::ProgressBar and an argument parser. It also handled the "save render to PNG" logic. These two parts needed to be split into their own sections:
- Render Library: Should contain all of the classes & functions required to queue up a render, retrieve it as a block of bytes, and probe the status (e.g. "54% complete")
- CLI Runner: Should use said render library. Provide the same exact (text) interface that existed; as not to break anything. The responsibility of saving the render to an image format (e.g. PNG) lives here.
This was actually much easier than I expected it to be, since most of the rendering logic was separated well (already) from the "TUI logic". Chopping up the old main() routine went quickly. An interface to use the render logic was put into a file render.h, which looked like this:
Some extra functions that didn't exist before were stop_active_render(), render_in_progress(), and num_cocurrent_threads_supported(). From an API standpoint, it's not nice to have to wait for a long computation to finish without some way to kill it prematurely. For the CLI Runner, a user could simply halt a render by doing Ctrl-C. But for the GUI portion, there needed to be a way to end a render via a button; without ending the whole program.
num_concurrent_threads_supported() is more of a "nice to have". In the GUI, I wanted to give my users a button they could press to max out the core/thread count. Having them guess this isn't really acceptable. C++ actually has a built-in function to retrieve this. It would be silly not to add this in, even if it was just a wrapper around some standard library call.
After finishing the splitting up, it was now onto the real important part: The Qt GUI.
Qt Time
At the time I started out, version 6.2.1 was what was available. Midway through 6.2.2 also came out; not too much changed. About a week after I formally considered this "released" Qt 6.2.3 made its debut. Qt Creator also had a few updates. Noticeably with a focus on better CMake support. None of these caused any issues whatsoever. But it is kinda funny to see the project you started from a template become a little out of date a few weeks later.
One thing I've learned when trying to make cross platform apps: make sure you develop for multiple platforms at the same time. This might sound obvious and you might be confused that I need to stress this. Let me explain further with some examples:
Do: Write your application with a "unified experience" in mind. Develop on desktop & mobile at the same time. In fact, develop using at least two desktop platforms.
When I was working on a Qt Widgets program that had to support Windows, macOS and Linux. I did this thing where I would use one OS as my primary dev environment (e.g. Linux), and use a second one as my primary test/verification environment (e.g. Windows). Changes would only go in if they worked exactly on both. Then at the start of next week, I would rotate out which two OSes I was using (e.g. dev was now Windows, test became macOS). Then at the beginning of the following week, do another rotation (dev=macOS, test=Linux). And so on and so forth. This allowed me to catch platform inconsistencies quickly.
For example, I found specifying the native colour picker widget wasn't working correctly on Linux/Gtk. And the Qt provided fallback was considered undesirable. So I got to make my own. Which turned out to be something our customers really loved in the end!
Don't: Completely write the app on desktop (only one OS), call it done, then claim "it should run on every environment perfectly fine" without verifying. If you do this, you're going to find out things will not work as you expect them to. There are actually parts of the Qt API that aren't 100% cross platform. For example: Qt Bluetooth. With iOS, you cannot use the Bluetooth classic API. And with Windows, you're not able to make your device act as if it is a Bluetooth Low Energy peripheral. In Qt's defence, the Bluetooth situation isn't their fault.
Another place that I worked, the deployment platform for the Qt application was an embedded linux tablet, but what did the other developer build the application on: Windows... This thing was to run in fullscreen mode. It looked completely inconsistent between development machines (e.g. different laptops), and when running on the actual box itself (which had a smaller screen). Inside of the code, I found all sorts of Windows specific #ifdefs, fonts (e.g. Tahoma), sizings and whatnot. IIRC, I was told Qt was picked for this project since it ran on the developers' machines (Windows), but also compiled on the desired target device at the time (the embedded Linux tablet). Though they didn't always verify their changes worked on the target device before merging the code...
Avoid: Writing anything that's platform specific. You might need to do this sometimes. If so, keep it as minimal as possible and wrap it in an abstraction layer. I was hoping not to do this for this project, but alas, I actually had to.
Now back to actually developing this GUI: I took a Desktop Linux & Android Tablet first approach, verified the work on macOS & Windows at the same time. Included the iPad into the mix once I had a solid base. And finished with it on my Android Smartphone. I did find my share of platform inconsistencies with Qt, issues with supporting multiple DPIs, and small vs. large screens.
Making the UI, and Making it Work
Starting out, I wanted to make sure that the UI was focused on viewing the render. There would be buttons at the bottom and some status info. You could select which scene to render from a drop down. To change the render settings, those options would be available in a pop-over menu.
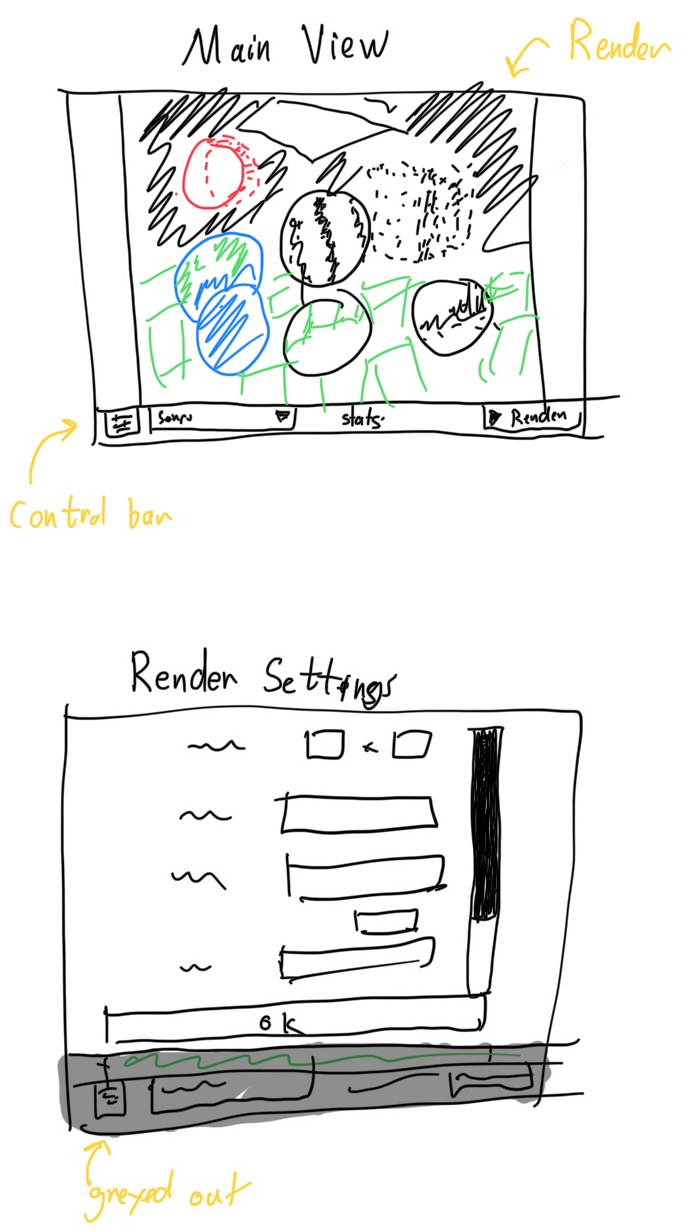
So I first set out to implement this using QML on the Desktop. This was mostly built out of simple controls such as Buttons, TextFields, ComboBox etc. Laying out the controls was mostly done with anchors . In a few small cases I used the Row/Column layouts. One of the more complex inputs that needed to be handled was size entry. I've seen it done where you have two side-by-side integer fields split with an "x" (or they're stacked on top of eachother). Others where you have one field but need to type in that "x" as if it were text. I opted for the former.
One of the safe-guards I added was that the user could not close the "Render Settings" popover unless all fields were filled with correct input. QML with it's "validators" feature made this easy. This was to make sure input could be more "safe" compared to using the CLI Runner.
Unfortunately, at the time of writing, I noticed there is a way to close this popover if you leave some invalid input. And then if you try to render: segfault. Time to go bug fixing...
Androidization
Everything looked fine on the Desktop, so next was to verify it was good on the Android Tablet. Setting up the Android SDK in Qt Creator was a breeze; nothing more than a point and click adventure. Once that's up, you should be fine to build and deploy to Android by simply plugging in a device (set to developer mode) and pressing the Run button in the lower left.

Very quickly, I saw what I had running on the desktop was mirrored on my tablet.
When running for the first time, you might notice that the app has an ugly default icon, or the name displayed doesn't look quite right. (e.g. my CMake project was called PSRayTracing_QtUI, and Android chose that). This might be okay for initial development purposes, but for distribution (i.e. in the Google Play store) this is going to get flat out rejected. To fix this, you'll need an AndroidManifest.xml file. Qt Creator actually has some nice simple support for the file. Though, getting one was a little confusing. I thought this would be done from the File menu. But it's actually tucked away in Projects -> Android builds... -> Build Steps -> Build Android APK -> Application -> Create Templates. Finding and clicking that button will add the manifest; IMO, it should not be this complicated for something so vital.
I really do like that Qt Creator has a built-in GUI editor for this (even if it is a little bit hidden). Setting and name and icon are easy. You can also add entries for permissions (e.g. Location). Please make sure to heed my warning about not touching the stuff in the upper left. I will elaborate on that further down the line. When I was first starting out, I put the value of 1.0 in there. Oh boy was that a mistake...
But now, the name of the app and the icon were showing up properly. I thought it would be good to test this out on my Android phone which has a much smaller (physical) screen than my Kindle tablet. Loading up the app looked fine in landscape mode. The popover for render settings didn't show as many elements in the scroll, but that's fine. When I turned my phone to run the app in portrait mode, something bad happened: the UI broke.
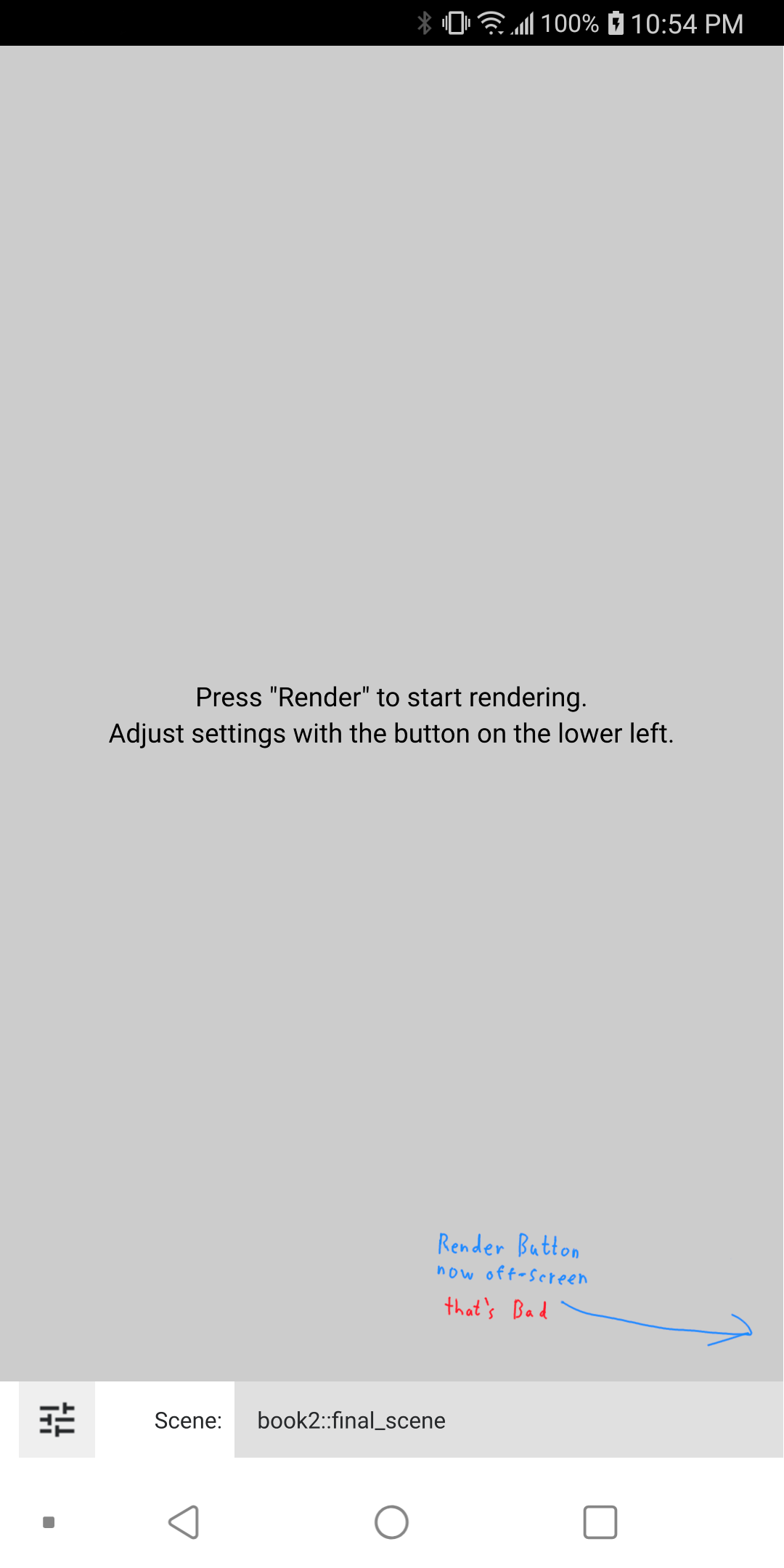
When developing initially on the desktop, I hadn't accounted for when my application is taller than it is wider. The scene select dropdown was way too wide, but it needed to be like that because scenes with very long names could get cut off. This would push the "render status" message off of the screen as well as the button to start/stop rendering. On top of that, I originally designed the Render Settings popover to be centred, with some fixed size padding on the left and right sides. This was no good as well now because all of the labels and text entries became super squished. Taking a short time to redesign, I came up with this scheme for the "Controls Bar":
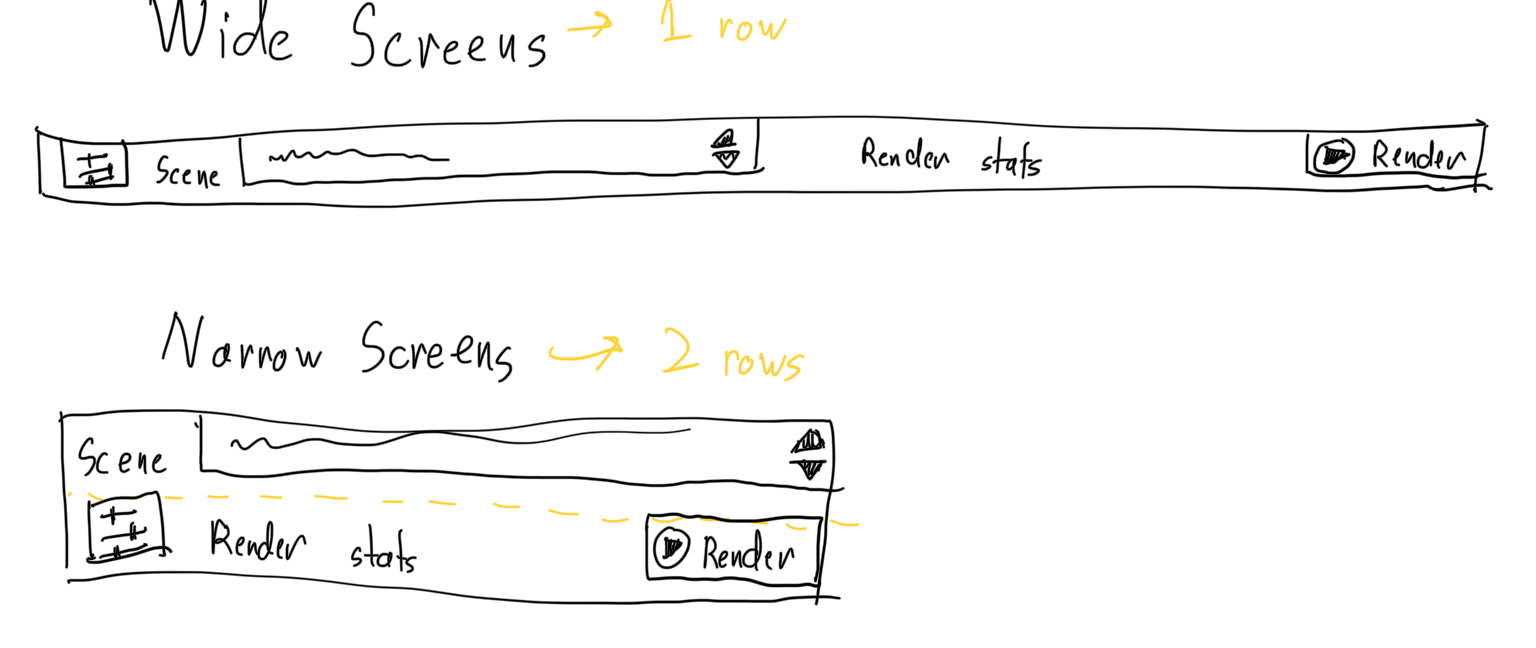
There would be two rows now. A single row tall when everything could fit. Two rows for narrow screens. Figuring what exactly was a sweet spot for this was a bit tricky. It was some trial and error. I decided that using anything less than 700 pixels would be considered "small" (in terms of width).
It worked well on Desktop; and then on Android as well!
This was achieved using using States along with AnchorChanges and PropertyChanges. I was hoping to instead define multiple layouts in separate files and use a Loader to swap out which one would be active. I had trouble understanding exactly how loaders worked, and was really concerned with signals/slots. So I opted instead for this solution where I shift around anchor points, padding, and sizing. It was a tad bit tedious. I do wish Qt had some better built in way to handle supporting multiple screens with adaptive UIs.
The Felgo framework has already solved this issue I believe, but I want to avoid pulling in more code which would break the "vanilla Qt as possible" rule I set out for myself.
Now with the app working well on Desktop computers, Android phone & tablet, it was time to make sure everything would work on iOS. I only had an iPad with me so I was going to focus on that display format. Since I had the app's UI working well on "small screen Android", I was going to assume that things would be fine on iPhone.
During development I never ran the app in the iPhone simulator because it was super-duper slow on my hardware. I then later purchased an M1 Mac Mini (way faster) and well, found out that iPhone portrait mode was busted. This was all after I considered the initial release ready. As I laid out earlier, don't make assumptions when dealing with cross platform development.
Tart Apples
Dusting off a Mac Mini from 2014, I updated the macOS version, put on Xcode and the latest edition of Qt. I got to work making the app running on my iPad. I was a little worried that things wouldn't go well, due to my hardware being nearly 8 years out of date (and knowing how quickly Apple likes to deprecate tech), but alas. I was able to build! But then I had a linking error...
This was odd since it was building and linking perfectly fine for Linux, Windows, macOS, and Android. Looking at the errors, it turned out the Render Library wasn't being found. Inspecting the build folders I found the static library was being built. Though, when the iOS app was linking everything it needed, it was looking in the wrong directory. E.g. the library was placed in Debug-iphoneos/ but it was expecting to find it in Debug/
(╯°□°)╯︵ ┻━┻
Why this was the case for iOS, and only iOS, I have zero idea. Someone is to blame. I'm not sure who though (I'm looking at you CMake). But to remedy this, it was simple: add a symbolic link to "fix" the problem. In CMake it's possible to add a pre-build custom target to run an action before some other step. Here's what was added:
This is inside of an if (APPLE) ... block. It's absolutely disgusting. I hate it. I want to get rid of it. It makes me feel bad. But I need it... Yuck.
{kind=link}
A note: When building your app for iOS, I'd recommend only using Qt Creator to configure the Qt/CMake project (for iOS), but do the actual building of the project and pushing to the iDevice in Xcode. This ended up being the path of least resistance for me.
After setting up all of the developer profiles and signing junk, I pressed "Run" in XCode, and was treated to the app running on the iPad:
Wat? That doesn't look right. It's. So. Tiny.
This had me truly confused. "But it worked fine on Android tablets... What the heck is going on here?" I thought. This was the first iOS app I had ever made. I spent hours scouring google searches, Stack Overflow questions, and Qt Forum posts to find out what the issue was: I didn't mark the app to be deployed on iPad as well. This is something you need to select in Xcode.
After that, voila, I had my app sizing as intended:
While it was good, there was another underlying issue: The "Targeted Device Families" option is a setting that lives in .xcodeproj. And for my case using CMake, this is actually a generated file that goes in the build/ folder. I'm not a fan of committing generated files, especially any build artifacts. I could always put a note in the REAMDE that says "If you're building for iOS, you'll also need to change this one setting to..." But this is detestable. It also doesn't work great when you want to get any sort of CI/CD involved. After some more googling, I did find a solution. I could set a target property in the CMakeLists.txt:
Magic numbers ahoy!, 1=iPhone, 2=iPad, 1,2=iPhone & iPad. Yeah, this is a little disgusting too, but it's what needs to be done. In fact, it would be nice if Qt's CMake stuffs did this automatically or provided a simple "build for iPhone/iPad/all" option.
For this pothole, I really don't know who to pin the blame on. All three Qt, Apple, and CMake didn't have the clearest documentation for this. It does seem like a common problem other developers might face since people tend to want to target as many types of devices as possible. I would have appreciated a " Common issues developers new to <X> face " section somewhere. But maybe the problem rests with me not knowing all the ins and outs of Apple/iOS development. I just want my app to work, and work well.
The app seemed to be functioning correct now. But likewise with Android, the display name of the app and icon weren't right and needed a custom one; without these a rejection from the Apple App Store would be certain. Getting this to work was another pain point for iOS.
Qt does have some adequate documentation when it comes to explaining some of the specifics for iOS They talk about how to set a custom app name, icons, launch images etc. But there's one major problem with that page; It does not have a single mention of how to do these things with a CMake build system. It only explains how to do this stuff via qmake. One could argue that "how to do this in CMake is out of the scope" but these are vital to get an iOS app to be considered finished by Apple's standards. It leads the developer to go and have to hunt for this information themselves. What I found out that I needed to add to the project was:
- An
Info.plistfile. Or the.invariant I used to generate one- This gives you the ability to set a custom app name
- An "Asset Catalogue". a.k.a known as
Assests.xcassets- This lets you use an app icon, which is called an
AppIcon.appiconset
- This lets you use an app icon, which is called an
- Some more Apple specific configuration to be in the
CMakeLists.txt
I can't recall how many days this took, but it wasn't fun. While this is mentioned in the "Platform Notes - iOS" document, I need to reiterate a fact mentioned above: none of this is mentioned on how to do this in CMake. If you read the page a bit more, it mentions that qmake does some of this for you (e.g. the generation of an Info.plist file). One suggestion I have for Qt to make this process less painful is to have a button, similar to the one that generates an Android Manifest, but one for iOS deployment. Oh, and as for all of the things I needed to add to CMake, here they are:
This stuff should really come default or be handled by Qt's CMake scripts.
It seems like I'm not alone in my troubles here. The third-party project QtIosCMake mentioned above tries to make this easier. While it's nice that others are willing to share the work that they've done, I don't think I'm alone in believing this should be provided by Qt.
Maybe the easiest part was generating all of the icons. I found this lovely site which does it for you. You'll need it since Apple requires your icon about 30 times over in different sizes.
Update Feb 26th, 2022: As mentioned at the top, some of these things I described here are actually known by the Qt Company and are actively being worked on:
- QTBUG-95838: Tracking ticket for "Improve experience of building iOS projects with CMake"
- QTBUG-93268: target_link_libraries does not work with a target name on iOS
- QTBUG-95837: Add default launch screen storyboards for CMake iOS projects. Looks like some code was merged and this ticket has been closed
- QTBUG-100833: Default iOS project to both iPhone and iPad deployment
But alas. After all this frustration, the GUI frontend was working great for the iPad! I had my fancy display name and fancy icon. Moving on, there were some extra features I wanted to add into the app to make the experience better for anyone to use:
- A button in the Render Settings screen that sets the resolution to render at, to the pixel dimensions of your screen
- The ability to zoom in and pan on a completed render, along with it being shown in a fullscreen mode
The second one was going to take a bit extra to make. Unfortunately, this isn't a control that comes by default in QML/QtQuick. I would need to build it myself. For the moment, I simply had the app displaying the render in the center of the app. I opted to work on the button first instead.
The Most Frustrating Button of my Entire Life
It's nice being able to view and generate renders at a native resolution. By default, the app renders at 960x540, which is reasonable IMO for simple testing. While a 1080p or 4K resolution screen is pretty standard these days for many desktop/laptop computers, there still are differences here and there; and it's more of a wild west for smartphones & tablets. If a user wanted to render an image at the same resolution as their device, I don't want to force them to have to know what their native pixel size is. I thought adding a button that reported the native pixel size, and pressing it would set the render size would be handy. I implemented it, but oh man, did it take a lot.
Going back to my Desktop -> Android -> iOS development process, I started again with Linux. QML has a built-in type called Screen that you can use to poll for display information. The width and height fields are what I wanted. Note what their documentation says:
This contains the [width|height] of the screen in pixels.
Using this I added the button into the Render Settings form and it worked. On my Lenovo X1 Yoga Carbon, The "Use Device Resolution" button said that I had an 1920x1080 screen. Pressing it sets the render size. Even better, the width and height properties of Screen support device rotations, and notifications in the event they change. So when I built & ran the same code on the Windows partition, put it into "tablet mode" and rotated the deivce 90 degrees. The button changed from saying my screen was 1920x1080 over to 1080x1920! Rotating it another 90 degrees made it go back. It was absolutely lovely.
Next, was to confirm that it was working on Android. When I put it on my phone (an LG Q7+), the button reported that I had a resolution of 311x823. What? That's not quite right... The specs of my phone say that I have a 1080x2160 pixel display. What could have been the matter? I then realized that all modern phones have really high DPI displays. The Screen object in QML has has a property called pixelDensity. Which on my desktop machines was reporting a value of 1.0. But on my Android phone, a value of 2.65 (IIRC). Now, multiplying these values:
823 * 2.65 = 2180.95 311 * 2.65 = 824.15
Wait... This still isn't correct. See, the Screen.width/height property returns something known as "logical pixels". They don't match the actual physical resolution. The Qt documentation doesn't say anything about this... The use of "logical pixels" is moreso meant to make sure apps scale properly across displays of different pixel densities. Okay, so I couldn't use the easier QML Screen object to get my desired "Use Device Resolution" button. Digging deeper in the Qt docs, there's also the original QScreen C++ class avaiable. In fact, look at the entry for size():
This property holds the pixel resolution of the screen
"Ah, I shall have my native screen resolution!" I thought. While it was a bit more work to get to the C++ API talking to QML, it wasn't too much. So I used QScreen::size(). And it reported 823x311... Once again, logical pixels... Not the real resolution.
Trying out the glut of properties available in QScreen, no single permutation, combination, or formula of them got me that native resolution I wanted. I tried everything I could think of. The next thing was something I didn't really want to do, but had to: Platform specific Java/Android native code. (dramatic music plays)
Adding in Java code and using it as part of the project wasn't that hard:
- Create a new
.javafile. Note that it needs to follow the whole folder hierarchy to work properly (See: https://github.com/define-private-public/PSRayTracing/tree/6ce9f2d6a06b33a935d2d666b941d28b09a44473/qt_ui/android/src/net/sixteenbpp/psraytracing, notice how it's the only file in the tree of folders) - Write your Java specific code in that file. Keep it short and sweet
- In the
CMakeLists.txtfile, add it as a project source. Make sure it's only added in when building for Android - On the C++ side, use a
QJniObjectto access the Java code you wrote
Here's how I did it:
What makes me a little extra sad is that the getRealSize() method is actually deprecated. And didn't see any alternatives. So now I'm being forced to write platform specific deprecated code just to figure out what the screen resolution is. And in C++, this was done to call the Java code:
Yeah, that does look a little clunky, but this is what you have to do if you want to call the Java/Android functions from C++. I defined another function QSize compute_true_screen_resolution() that will call the above block only when building for Android (via an #if defined(Q_OS_ANDRODI)...).
After all of this strife, I loaded up the app on my smartphone and as I had hoped, the button now said "Use Device Resolution (1080x2160)". I rotated the phone 90 degrees and it changed to match the orientation. It had worked! Loading it on the Kindle, it gave me the expected resolutionl. All was well, I just had to confirm this worked on the iPad and I would be good to go.
I loaded it up on the Apple tablet, which was using the QML Screen object. It said I had a resolution of 1024x768. What... no... The iPad I was using has a resolution of 2732x2048. And if I recall correctly, Screen.devicePixelRatio=2.0 on the iPad. That doesn't math right. Once again, I didn't feel trusting of the of the value reported by Screen, so I did some Google searching and I was pointed to using the nativeBounds from UIScreen
As a C++ developer, looking at Objective-C code absolutely scares me. But it's what we need to use to call these methods. But thanks to the compiler alchemists at Apple, they were able to put together a homunculus called "Objective-C++". Simply put, it allows the two languages to interoperate with ease. Here's the code I wrote get the screen resolution using native iOS calls:
At the beginning, the dim line is pure Obj-C. Then with native_size, I'm accessing the fields of an Obj-C object, though putting them into a C++ variable. Later on I'm using the clause of a check, from Obj-C, to then call a function on a C++ object. This is actually really nice. Way easier to work with than the Java-C++ interop.
What is a little concerning though is the future of Objective-C++. It seems like Apple has deleted their documentation for the language from their website. So if you want to read it, you need to find a third party source (such as archive.org). Some other cross platform frameworks like Dart/Flutter use Swift as their iOS native language (Kotlin for Android as well). This might be the future for Qt too, but it is not known yet.
For the integration into your project, it's even a bit easier than Android/Java:
- The code needs to go into either
.hor.mmfiles. These can be put in any folder. No complex hierarchy required like Java - Add the source files to the
CMakeLists.txtlike you would for any other.cppor.hfile. Make sure their only compiled in for iOS (if (APPLE) ...)
And from there, you only need to call the functions you made.
So now, I tried to run the above snippet to get the screen size. And... it also returned the value 1024x768...
I was really upset as to what the issue was here. After working on some other task to let my brain goo simmer for a little, I revisited this a few days later. This time around, instead of making a Qt app. I launched Xcode and made a 100% native iOS app. It was to use the snippet above (sans the Qt code) and report what the screen size was. Doing just that, I had it print the result nativeBounds to NSLog. It reported 2732x2048.
Success! But... Why was this only working in the test program? Well, after some more googling, I found my true answer. You see, my project, when building for iOS, was actually missing something vital: a "Launch Screen". The dummy app that I made in Xcode had one in by default. Whereas my Qt project did not. If you read the Apple docs, it mentions that this is vital:
... Every app must supply a launch screen.
I took the launch screen I made in the demo app, stuffed it into the Qt project (which needs to be specified in the Info.plist.in file), re-built and launched the app on the iPad. Boom. There it was. The button was now saying "Use Device Resolution (2732x2048)". Rotating it worked as expected.
In fact, I don't even need the iOS specific code anymore. Both the QML Screen object, and the C++ side QScreen no wreported the expected value of 2732x2048. I'm leaving it in though to serve as an example of how to do iOS native interop with a Qt app.
To be fair to Qt, if you go back to the Platform Notes - iOS document above, it does make mention of a Launch Screen/Image, it is purely in the context of working with qmake. Actually, not a single mention of CMake exists in that document at all. This makes it really hard for people who want to use this build system.
To think, the days of frustration that I went through to get this simple button working on iOS, was a missing configuration/deployment file. Which sole purpose is to trick the user into thinking apps load up fast. That is generated when using qmake, but is missing when using CMake.
(ノಠ益ಠ)ノ彡┻━┻
After this, the app was working as expected on the iPad. I didn't have an iPhone to test with, and the simulator was unusable on a low-end 2014 Mac mini. It was working well for Android phones, so I think it would be safe to assume it was fine for smaller iDevices (spoiler alert: it wasn't).
The Image Viewer
Above, I mentioned that I wanted to add in an extra picture viewer to the program. I don't think there's much to go on about here compared to that infernal button. It was mostly a lot of work in simple QML. All I wanted was a basic image viewer that let the user full screen the render, zoom in and out and move around the viewport. There would also be some extra buttons off to the side to reset the zoom values.
It did take me about two weeks to get something that was satisfactory; but there definitely is room for improvement IMO. I did have to sacrifice one of my "desirables" due to a bug in Qt. I know that this is a more complex built up control, but I am a little surprised that Qt didn't have something off the shelf, or a "cookbook" example that could be integrated. Since this does seem like a very common thing to have in apps.
There's a lot of gory details here that I don't want to go into. If you want to read the source code (or use it in your own project) it's available here It did take me a bit to figure what the correct hierarchy of controls needed to be. Because I also had some Buttons occupying the same area as a MouseArea, I needed to fiddle with the event propagation. Here's the basic outline:
One feature I had to strip out of this was the "make app go fullscreen" when an image was in "pinch-zoom-pan" mode. This was actually because of bugs that I found in both the Android and iOS versions of Qt. It's possible I could have put this in selectively for Desktop, but I really don't want to add platform specific QML code. The function call to do this was QWindow.showFullscreen(). Very easy. Toggling it on and off worked great for Desktop. But what was wrong? Let's go with Android first:
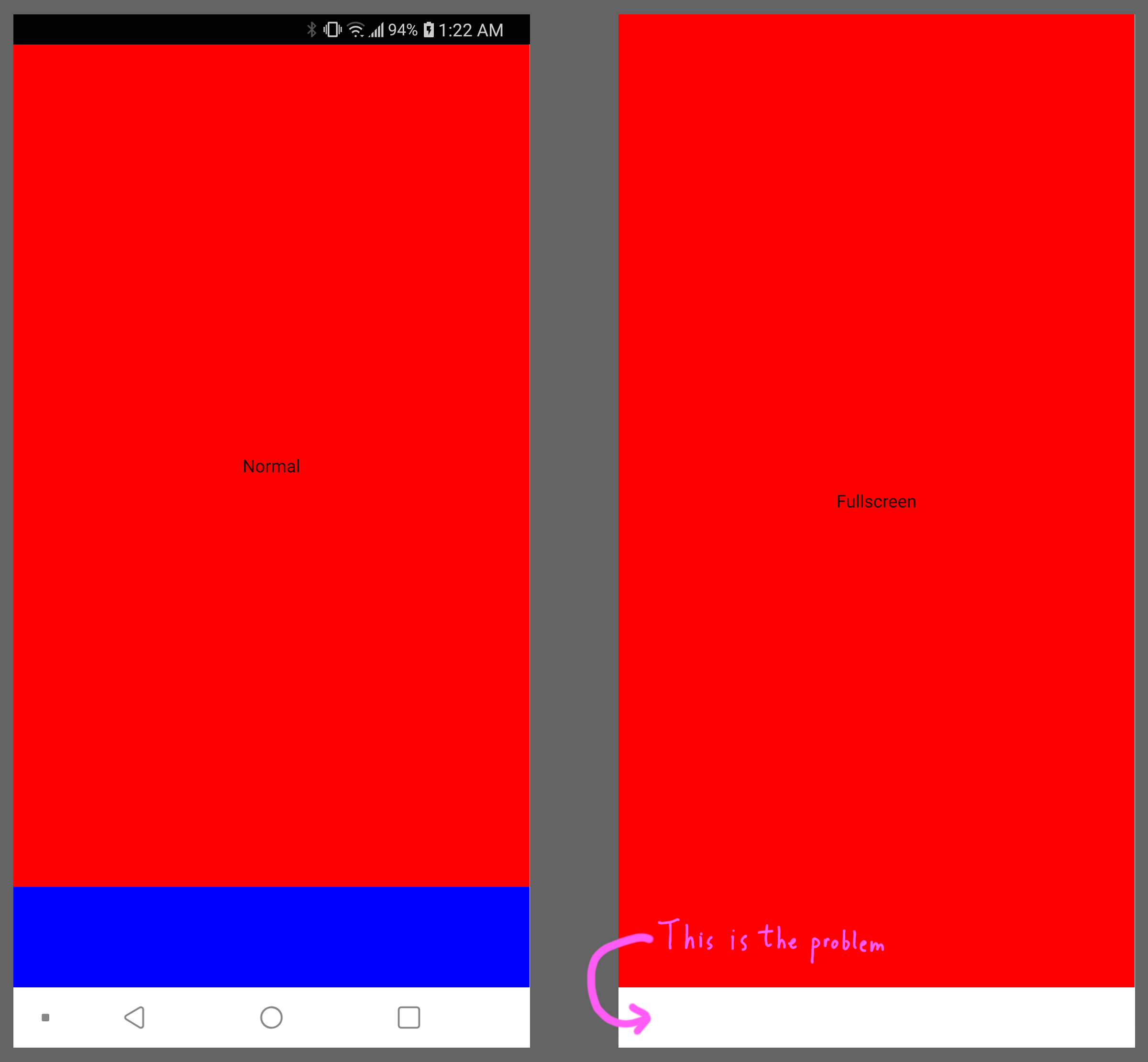
I made a little dummy app that would call the method above. The red zone was supposed to be where the image would show. The blue zone would be the control widgets/buttons. When full screening, the top bar (the notifications, time, battery, etc.) went away. The blue zone disappeared as expected. While the Android system buttons below disappeared (e.g. Back, Home, Show all apps), the white background behind them did not go away. So on my phone, I was left with a blank white bar at the bottom. This is ugly. I loaded the same code up on the Kindle to make sure there wasn't something wrong with only the phone, but the same issue was happening there.
I was still hoping that this would be working on iOS. Using the same sample app, going full screen worked as intended. I was full of glee. But then when I exited full screen, it was even worse. Take a look:

The layout went completely bust. This is unusable, so I had to completely scrap this feature.
Being a good little developer, I made to file some bug reports for this:
- Android's: https://bugreports.qt.io/browse/QTBUG-99046
- iOS's: https://bugreports.qt.io/browse/QTBUG-99047
As for things I'd' really like to improve in a 2nd version:
- When zooming in/out, it doesn't keep the viewport centered. It zooms based on the top-left coordinate, which doesn't feel too natural. E.g. If I were using the scroll wheel on a mouse, the user would expect to zoom on where the mouse is over; this doesn't happen. Or when pinching on a touch screen the device, the center point of the two fingers should be "zoom focus".
- The math for this should exist already in C++'s
QRect. It has a lot of useful functions. But if you look at the docs for QML'srecttype, it's nothing more than a data container. As much as I'd like to keep all of the logic for this widget in QML, if I want to make this easy on myself, I'd need to write the logic in C++.
- The math for this should exist already in C++'s
- When zooming out there, sometimes the image might go out of the viewport. This is really minor and fixed quickly by the user making any other zoom action.
- If the user starts to pinch-zoom-out on the image, it should put the image into pinch-zoom-pan mode. Right now they have to double-click or double-tap on the render
- Making it actually go fullscreen; but that isn't possible right now.
- Maybe add in a button to exit the pinch-zoom-pan mode. Sometimes the double-taps weren't always registering on my Kindle Fire (but they were fine on the Android Phone and iPad).
With both the "Use Device Resolution" button and this image viewer done, I thought the app was now good enough to be formally distributed on app stores. I'll get to that in a moment, but I did want to cover some other speed bumps that I came across.
Use of Apple Pencil is Busted
This is honestly kind of a bad one; pressing any control with the Apple Pencil will not work, and leave the control in a "pressed down and stuck" state. Though if you press the control with your finger the control will still start to work again like normal. E.g if you tap on a Button, it will look like it's been pressed down, but it will then be stuck in that visual state, without the button's action being executed. If you try to tap on a dropdown list it won't open up. It will be "stuck down" until you use your finger.
While the use of an Apple Pencil isn't required whatsoever for this app, you cannot use it with any Qt 6.2 app (or 6.0 and 6.1 AFAIK). If you own one of these pen inputs or have ever seen anyone else use one, you know people like to tap every single control with the pencil. They do not want to let the stylus go, as it would interrupt any flow they have going on.
As someone who would like to make art focused apps with Qt in the future, this is absolutely critical to be fixed. And too Qt's credit, they've marked it as such: https://bugreports.qt.io/browse/QTBUG-98936
Another component of the Qt tablet/wacom interface was broken for me when I was trying to port another app of mine from Qt 5.15 to 6.2. Qt did fix the issue promptly after I reported it, so my hats off to them for making it right. How input events work in Qt 6 did change, so it's not too much of a surprise that things got accidentally knocked out (e.g. tablet pen use).
SVG Icons (for Buttons) are Fuzzy
This is one you can file in the "no one is going to notice unless they look really closely at the pixels" category. But nonetheless makes the app feel less refined.
Remember the dawn of when the Retina display first happened? Everyone loved it so a lot of other devices and screens started to become very-very high resolution. This created a problem where all the icons every app was using looked really bad. This was due in part everyone was using bitmap files for their icons, which were being scaled up on these high DPI displays. Everything was ugly and fuzzy thanks to bilinear filtering algorithms being applied directly onto the pixels.
One solution was to provide the icon in multiple resolutions and then dynamically select one dependent upon the display detected. But we already had another solution ready and available to use: SVGs. Scalable Vector Graphic icons were (and still are) great since scaled up and down (hence the name) and look perfect on every screen type. That is, if the SVG renderer is working properly.
The icons I used for the app were grabbed from the famous Google Material Design Icon set. They are well known to look good and work great. Putting them into my Qt app they were rendering correctly on desktop. Where I had non-high DPI displays. When I put it onto the Android smartphone, Kindle Fire, and iPad, they all looked good at first glance. But when copying over a screenshot and inspecting it back on my desktop, I noticed some upscaling blur around the edges:
![]()
Checking with my eyeballs close to the screen, I could see some fuzz on these devices as well. If you can't see it well here, open the image in a new tab and zoom into 100%, or even 200%. Notice how the text "Render" is crisp, versus the icon to the left of it. The settings icon (off to the far left) should also be a bit crisper too.
When I found the issue I did report it, but then it was soon closed as a duplicate. With the fix for the other ticket being slated to be put into Qt 6.2.3 (I was using 6.2.2 when I found this issue).
Now at the time of writing this blog post, 6.2.3 was released. Verifying this fix was in the release notes, I was eager to get this fix working. I spent all of the time updating Qt, recompiling for Android. And.... It's still broken.

Once again, not a deal breaker for getting this app out the door, but this bug can make any app feel less professional. It might be that the SVG scaling is fixed for the Image control, but the fix isn't truly complete if it's not working for Button.icon. (I have refiled the bug)
Accidentally Implementing A limited ScrollView
For the "Render Settings" popover and the "About" page, there isn't enough room to display everything in the frame, so I created a custom QML control called VerticalScroll. If you have an area in QML (e.g. 200x900) that's larger than your screen/window provides (e.g. 300x500), you can wrap the VerticalScroll over it to create a viewport that you can scroll up and down. If you don't have enough room, a scrollbar will appear off to the side. If you do, then it will go away. If your window/screen resizes and you have enough or don't, it will update to make everything nice and flush. This took me about a week to make. This was because I thought that Qt's provided ScrollView wasn't working.
Turns out this was completely unnecessary and I was using ScrollView wrong. I only found this out after I started writing this document. When I initially used ScrollView, it was like this:
I could move the RenderSettingsForm in the viewport. But then after lifting my finger up, the contents would be stuck in place, even if it was out of bounds. It also didn't feel well when flicking on a touchscreen (e.g. no acceleration/deceleration). So I set out to make my own scroller based upon Flickable. A few days later, VerticalScroll was complete and integrated.
To get what I wanted, this was actually the correct thing I needed to do:
I do need to fault Qt's documentation here for not being clear and possibly a little misleading. Reading the "Detailed Description" section for ScrollView It says this:
ScrollView provides scrolling for user-defined content. It can be used to either replace a Flickable, or to decorate an existing one.
If you look at the first example right below that line, where there's only a Label element as a child, you'll get that undesirable "sticking" behavior I was getting. The code snippet right below the first one does use a Flickable, but it's actually derived control. The wording of this documentation is confusing. I think a better documentation string for this would be:
ScrollView provides scrolling for user-defined content. The content should be placed inside of a Flickable, which is then placed inside of a Scrollview.
I also think that the first example with the Label should be scrapped or updated, as it's misleading.
Another alternative to this would be to automatically include a Flickable under the hood for any of ScrollView's content, but that's a whole other political discussion that could break a bunch of existing code.
Text Scaling (and UITheme.qml)
This is a pretty brief thing to talk about but it's something worth discussion IMO. This is probably helpful even outside the realm of Qt/QML apps.
When I first moved this app over to my Android tablet, the text on screen looked really tiny. It was still readable, but not pleasant. I believe this was due to the fact that the Kindle Fire had a higher Screen.devicePixelRatio (1.5) compared to my desktop monitor (1.0). So I needed to bump up the font sizes a little if I was running on a high DPI display. The solution was really simple: multiply the font size by a certain scaling factor, if running on high DPI. It also wasn't too much in the code.
When I started out the app, I put all of my UI styling stuff into a QML singleton file called UITheme.qml . This includes colours, font sizing, spacing, padding, etc. I really recommend following this pattern instead of leaving this information only where it's used. This way you have a single source of truth for all of your styling needs. If later on you want to support multiple styles your life will be much easier.
Inside this UITheme.qml, there lives the properties that control font sizes:
So first for the Kindle I did this:
It looked the same on Desktop (as expected). Putting it on the tablet, it looked great. Next on my Android phone which has an even higher DPI (2.65 IIRC), the text was definitely larger, but too large as it started to now go off screen. But, the fix was even simpler: clamping with Math.min().
Once again, reloaded onto the Android phone; it looked good. Lastly, double checking on the iPad, it was perfect there too. Using a maximum font scale for 1.8 is what seemed to look best across all screen types I was testing on.
Getting it up on Google Play
Writing software is easy. Distributing it is a pain in the ass.
While I had built about two Android apps prior, I had never actually put them up on the Google Play store before. Nothing ever went far enough until now. So this was my first time experiencing it. One of the more important things was "version coding" which I'll talk about soon, but let me go over my other notes first:
- To sign up as a developer, there is a flat fee of $25. While some might not like it, I think it is very fair as it can help reduce spam and abuse in the Play Store. I can't seem to find this old article from years ago, which showed off how in the Windows/Microsoft app store used to be a plague of fake VLC apps that went on for pages. This was the only thing I could dig up: https://malwaretips.com/threads/fake-vlc-for-windows-8-1-apps-in-windows-store.19597/
- Once I was ready to release my app, it took about an entire week for it to receive an "E for Everyone" rating. The app would not be published without it. I read someone that on average it would take 3 days to review. But maybe being a new developer, they gave it some more scrutiny. Because of <CURRENT_WORLD_EVENT> there's also the possibility of that they have <STAFFING | LOGISTICS | RESOURCES> shortages right now.
- There is a somewhat lengthy questionnaire you need to fill out. Prompts like "Do you have in-app purchases?", "Does this app have user generated content that can be shared with other users?", "Is this a dating app?" Etc.
- Writing down a "Data Collection & Privacy" policy was kinda odd IMO. I'm required to have one. Even with the fact that this app collects no data whatsoever. This could be one of those things required by the much feared GDPR, but IDK. At most, the only data this app would store on your phone is PNG of the render in a temporary location.
- There are a few things that Google lets me know, but it's restricted to merely metadata. E.g. what kind of model of phone installed the app, geographic locations, etc.
There are many different types of Android devices out there. The Google Play Console reported to me there's a little more than 20,000 types of devices in active use. Qt for Android lets you build for Intel and ARM based Android, and 32 bit and 64 bit; so that's 4 different configurations. Most smartphones are of the ARM flavor. Whereas the Intel devices are probably Chromebooks. Your app will also target any device that's Android version 6.0 and up. The Google Play Console reports that PSRayTracing for Android can run on 15,000 different devices.
While it may not seem great that you're missing out on 25% of what's available, keep in mind that this number is not weighted as to how many total devices there are (not device types, but units). Android 6 was released back in Oct. 2015. So it's probably more likely that you're able to target more than 98% of the Android devices out there in use; all made within the last 5. You're well covered.
Something you need to keep in mind is that for each release of your app (e.g. v1.0, v1.1, v2.2) you technically can have 4 versions of each because of the Intel/ARM 32/64 bit stuff. (e.g. v1.0-x86, v1.0-x86_64, v1.0-ARM32, v1.0-ARM64, ... v2.2-ARM64). This is what Google/Android considers a "Version Code". These must be fully unique.
What you do for this code is completely up to you, but Qt does have a recommendation. Reading their Publishing to Google Play document, they have a recommendation for how to do version coding. Unfortunately, you need to build your programs 4 times over, once for each architecture type. IIRC, Qt 5 does support multi-ABI builds. I'm not sure where that went in Qt6. No biggie honestly. Back to version coding, here are some important things:
In your AndroidManifest.xml do not touch that Version Codes entry that is automatically generated. Leave it as is. In fact, up above I made sure to make a note of it in the screenshot of the manifest editor.
You see, when I started out, I was kinda dumb and changed that -- %%INSERT_VERSION_CODE%% -- value to 1.0. Oh boy did that cause some troubles. When I built my application, no matter what architecture, the "Version Code" was always set to 1.0. And when uploading to Google Play, I kept on getting an "Error, version code already in use". I had no idea the generated version code kept on being 1.0 until I created a new dummy project and saw that I needed to keep that to the default -- %% ... Qt folks, if you're reading this, please add a warning message to the field right below that you should not edit this field unless you know what you're doing. Or at least hide it.
One of the other pain points is "how do I get those version codes there?". Well, here's the other annoying part: You gotta do it yourself. Qt suggests on how you should version code, but they won't do it for you. Nor do they provide a code snippet (CMake or qmake) to work off of. They recommend to follow the pattern of <Platform><ABI><AppVersion>. platform=0 for ARM, or 1 for Intel. ABI should be either 32 or 64, and AppVersion should be some sort of numerical code that corresponds to your app. E.g. use 110 for your app's version is 1.10. And yes dear reader, that would lead to a problem for the chance you have app version 11.0 But from there, you can simply go from version 10.x over to 12.0; Just like how Microsoft skipped Windows 9, so can you!
That is unless you had an app version of 1.20, then you can do 10.x -> 13.0! But what if had to do 30 minor releases for 1.x and used a 1.30? Well my friend, just jump up to 14.0! As you can see, we're going to be here a while... The chance that you'll need to do any of these is slim to none unless you're releasing a new minor version multiple times a day. Honestly, don't worry about it and follow this versioning scheme and do the "big leap" only if need be, which should be rare.
Let me save you some trouble and give you the snippet of CMake that can do this for you automatically:
This is one of those things that should be provided by Qt out of the box, or at least included in their docs. Not having this readily available and easy to integrate is -1 point for Qt. Like I stated far above, I can only hope that this is no longer the case in the future and this blog post becomes outdated.
Lastly, don't forget to sign your builds. This can be done in the same section (Projects) where you generated the AndroidManifest.xml (The CMake Configuration). This does feel like one of those options that's more hidden than it really should be.
With all this out of the way, I was able to successfully publish the app to Google Play. And after three weeks, I've got a total of 20-ish installs. It's something. :]
![]()
Not Getting It Up On Apple's App Store (Updated: it now is)
Update Oct 23rd, 2023. This section was written more than a year and a half ago. Recently I've decided to bite the $100 fee to have the app published in the Apple App Store. But I also do not want to change what I haven written so readers can understand why it wasn't available on Apple's store up until now. I still stand by my belief that the fee is unfair to developers who want to publish free/noncommericial apps.
This is a real sore spot.
PSRayTracing's iOS version is not up on the Apple App store and won't be in the near future. That is, unless something changes. I spent a lot of time, effort (and money) trying to make sure that this app ran well on my iPad. The app isn't going up on Apple's store because of the fee for developers (and the policy surrounding it). I'm not talking about the well known 30% cut they take on transactions; PSRayTracing is a fully free application (both as in speech and beer).
If you want to publish any app of any kind (commercial or not) on the Apple App store, you need to sign up for the "Apple Developer Program" The fee for this is $100 per year. For someone in my situation, this makes zero sense.
I understand that similar to Google Play's one-time $25, this can help prevent abuse and make sure that only people serious about making apps can be published. But at this price point it's not really fair for what I want to do. To their credit, Apple does offer a fee waiver to certain groups like educational institutions and non-profits (only in specific countries). But working on this as an individual hoppy project, I do not qualify for this fee waiver.
I tried reaching out to Apple (including a college friend of mine there) to ask if there was some way I could get a fee waiver due to the nature of my app (free, open source, educational, benchmarking tool, etc). But they only had this to say:
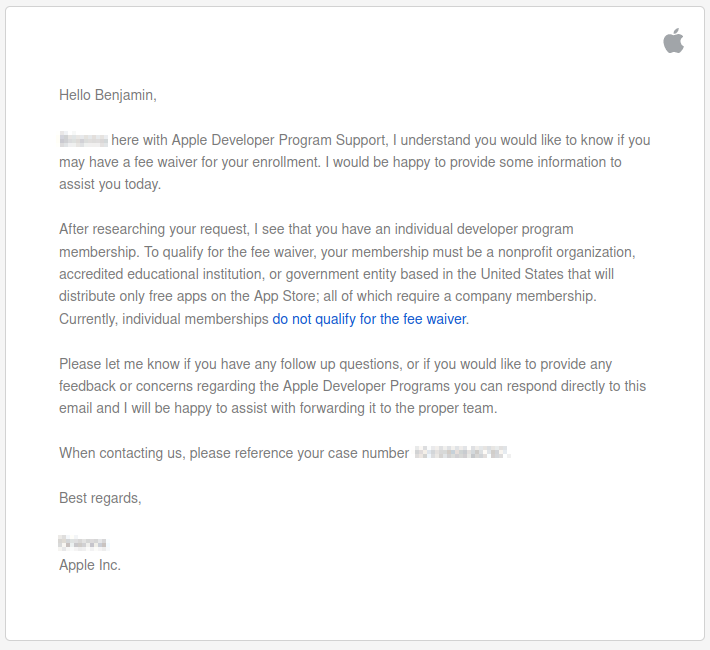
Within the past three months, I have spent more than $1,700 on Apple products. iPad Pro, M1 Mac Mini, and an Apple Pencil. Partially for work and part for fun. I've really enjoyed these tools. I spent a great amount of time making sure that the app would work with the iPad. To pay another $100 to get the chance to put the app up, is simply just unreasonable at this point.
Part of this could be my own fault for not doing full research on how app stores work before embarking on this project. But then again, I really wanted to test the cross platform nature of Qt, so that's why I maybe completely forgot about distribution and was focused on just getting the app working.
Do I have the financial means to pay for this? Yes, I do. As noted by my recent purchases, this is well within the range of my checking account. But once again, something about this just doesn't seem fair based on principle alone. I'm thinking about all of the younger programmers (e.g. the 14 year olds) who could be starting out on the path to becoming a software developer. Sure, anyone can make a web or desktop application and self-publish. But some people are not interested in that. Some people want to make native apps; because this is what interests them. Maybe all they have is a years-old low-end smartphone in their pocket because they couldn't afford anything else. They know that having any kind of app up in an online store is a gateway to a first job, internship. Possibly, they want to build upon an idea and start a company. I can't help but feel that this $100/yr fee pushes younger and less fortunate people out.
This is not me right now. But I used to be someone like that in the past.
I am confident in the future I would like to publish my own commercial apps to the Apple App store. At that time, then paying the developer fee would make sense to me. I would try to submit PSRayTracing's iOS port to Apple at that time too. Or if the cost was much less (e.g. $25/yr), or even one-time like Google, I would have no issue paying whatsoever. At the moment though, I will not. I'd rather be writing about issues with configuring plists or ranting about confusing CMake/Xcode settings rather than writing this section. And as I've stated before, I hope that these words become out of date.
( ಥ_ಥ )ノ🍎
I hope that someone from Apple is reading this and can help address the problem at hand.
If you want to run go and try out PSRayTracing for yourself on your iPhone/iPad, you'll have to build it yourself from source here . I don't have anything in the README now, but should in the future have detailed steps. Though, it should be straightforward if you've ever worked with Qt for iOS.
Final Thoughts
Very much, there are bugs I could fix, and ones that probably need to be. I never got to test this on a desktop with a high DPI display. If someone has a Retina MacBook Pro, hit me up yo. I'm going to be logging tickets in the issue tracker on GitLab. At this point, I really want to move onto other projects. So this is going onto the back burner once more. I'm still very happy with what I was able to accomplish here.
I'm sure there are some things I forgot to write down along the way, but let me share with you some things that I learned:
- Not so much different platforms are going to be your problem, different screen sizes, resolutions and pixel ratios will
- The tiniest little features can give you the largest headaches
- Right now, I'm thinking I should have put a drop down with a list of common resolutions instead of the "use screen resolution" button. Could have saved myself three weeks of work...
- Distribution & configuration is always more of a pain for software, rather than writing it
- With all of the concerns of Android fragmentation I hear about, iOS was much harder to work with. It feels like there so many more edge cases
- If you have anything platform specific, wrap anything & everything in an abstraction layer. Even if it's more work and may seem tedious right now, it can save you in the long run. Then if the platform specific issue goes away, you can still use that wrapper, or easily refactor it out. And if you ever need to add an extra platform, you'll have an interface to plug in any platform specific code into
- Make tiny little test projects for ideas rather before cramming it into the existing larger project
- I've had managers who didn't like this because "I wasn't working on the product" But I've found this to be a much easier way to work, especially if the feature you're working on is hidden behind layers that take upwards of two minutes to access.
Talking about Qt for the moment, 6.2.x is supposed to be their latest LTS release. With some of the bugs that I found while making and testing this GUI give me a little reservation about committing to it; at least for what I want to make. For example, the Apple Pencil one is really bad. It does steer me to stick with the older LTS release (5.15.x) for the moment. Though the updates to 6.2.x keep on rolling in at the rate of once every 1-2 months, coupled with changes to Qt creator as well. I think that for most people's cases, Qt 6 is probably the way to go as it can only get better. Be careful though.
While it is nicer to see much better CMake support as it is the de facto C++ build system, at times, it really does feel like a second class citizen compared to qmake. There's a lot of extra build script code that I needed to bolt on, which IMO, should happen automatically with Qt's CMake support. It needs to work out of the box. I shouldn't have to go digging for hours and resort to 3rd party sources. CMake is now the build system the Qt uses internally for itself, And while writing this post, Qt Creator 7 beta was announced, dubbed the "CMake update". I still have yet to take it out for a spin.
Also while I was mid way through this project Qt Creator 6 was released. I couldn't help but notice the starter project template's CMakeLists.txt file that are now generated want you to shove the .qml source files in that. Instead of putting them into qml.qrc like before. So now my project is slightly out of date... 🙃
But once again, this is not meant to be a stab at Qt, even though I can be very critical of it at times. I don't think there's any other cross platform framework out there that's as mature as it. I have been tinkering with Dart and Flutter, but there are areas where it does lack. I've done much with Gtk too in other free time projects. I really do love working with Qt and glad I've been able to start making a career out of it. If I didn't care for Qt, I wouldn't be filing bug reports. Or writing up a post mortem of this length.
I wanted to show others the processes of what goes into making a cross platform mobile/desktop app with C++. And perhaps, provide a framework for them on how to get started. I do also hope that the Qt folks read this to study the possible pitfalls one could encounter (and how to get out of them). Whether it be the UX of Qt Creator, improving CMake support, and bettering the documentation. Like I've said a few times before, I hope the contents of this blog post becomes out of date.
Once again, if you want to see the source, it's over here on GitHub in the qt_ui/ folder. Though, I do most of the work over on GitLab. There's some cleanup work that needs to be done, so PRs are always welcome, check the issue tracker for tasks. I'm always willing to help out someone who wants to help me out :] . If you have Android and simply want to give it a run, here's the Google Play link:
![]()
Hopefully in the future it will be up on Apple's store. EDIT Oct. 23rd, 2023: AND IT NOW IS!!:
I believe this has been the longest ever article I've ever written. For those of you who read it all, thank you for taking the time. Please go out there, have fun, and make something great.
Epilogue
Days after having this article's content written, I got to try out the app on a Pixel 6 Pro. It performs superb. But look what happened to my app icon. All other app icons were filling the full circle. PSRayTracing's was being scaled down to fit. It "fills" nicely on the LG Q7+ and Kindle Fire, which have more square icons.
![]()
Yay. More ugly inconsistencies. 🥳